Introduction
機器學習是一門技術,可以讓電腦自動學習、改善和自我改進,讓電腦獲得知識,而不需要明確的程式指示。它涉及到兩種不同的學習:監督式學習和無監督式學習。在監督式學習中,我們會將問題與正確答案一起提供給程式,以便找出兩者之間的關係。可以分為回歸問題和分類問題。而在無監督學習中,不需要知道資料中每個問題對應的解答為何,而是由程式從資料中找出 pattern 和結構,方法通常為利用資料中的變數關係進行分群演算法(clustering algorithm),以及 Non-clustering algorithm,也就是 Cocktail Party Algorithm。
What is machine learning
Arthur Samuel (1959) : Machine learning gives computers the ability to learn without being explicitly programmed.
Tom Mitchell (1998) : A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
假設你想讓程式學習垃圾郵件過濾器。
- E: 程式觀察你標記的郵件為垃圾郵件或非垃圾郵件
- T: 程式獨自區分郵件為垃圾郵件或非垃圾郵件
- P: 過濾垃圾郵件的成功率
因此,T 的 P 應該在 E 的訓練下有所提升!
Supervised Learning
在監督式學習 (Supervised Learning) 中,我們會將問題與正確答案一起提供給程式,以便找出兩者之間的關係。監督式學習可以簡單分為回歸問題 (Regression Problem) 以及分類問題 (Classification Problem)。
Regression Problem
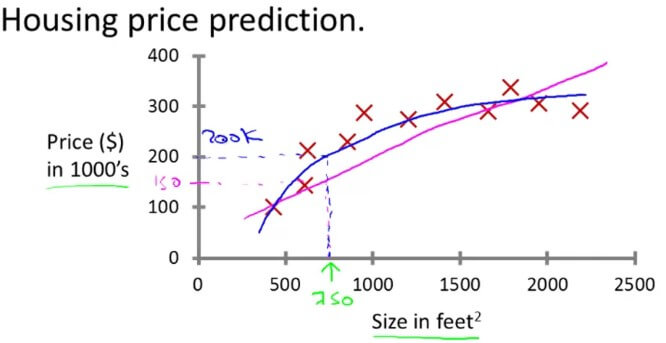
在回歸問題 (Regression Problem) 中,我們希望利用特徵 (Features) 來預測連續結果 (Continuous Results),也就是將輸入變量映射到某個連續函數 (Continuous Function)。 舉例來說,我們想從現有的房地產狀況,來判斷手中的房產應該用多少的價格賣出,才會符合市場需求:
此時 (feature) 為 Size in feet square,而 (result) 為 Price 是一個連續輸出,我們可以設定學習演算法使資料符合直線或二次函數。
Classification Problem
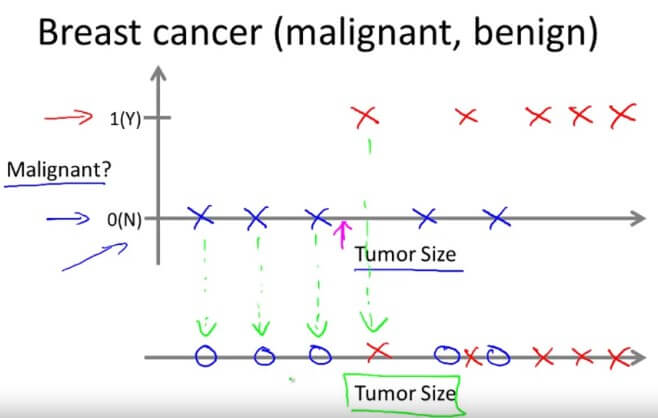
在分類問題中,我們希望利用特徵 (Features) 來預測結果 (Discrete Result),也就是將輸入變量映射到獨立的類別中,例如我們想從病人的腫瘤大小,來訓練機器判斷腫瘤是良性或是惡性時,此時結果可以用 0 或 1 表示,所以是分類問題。
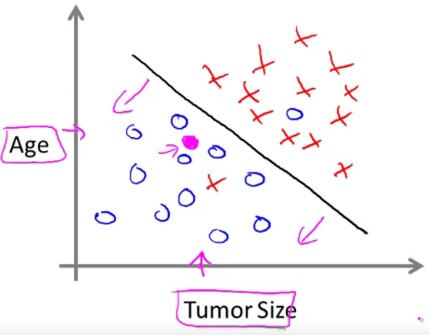
在分類問題中,可以有多個特徵 (features) 和結果 (results) 出現,例如可以用腫瘤大小、年齡,甚至是無限多的特徵來學習預測腫瘤的好壞,而結果也可以有多種出現,例如預測的腫瘤可以分多種型態,可以用 0、1、2、3 …… 來分別代表不同種類。
Unsupervised Learning
無監督學習 (Unsupervised Learning) 不需要知道資料中每個問題對應的解答為何,而是由程式從資料中找出 pattern 和結構,方法通常為利用資料中的變數關係進行分群演算法 (clustering algorithm),例如 Google News 每天自動分類並匯集相關新聞於不同新聞網站的 URL、從上百萬的 gene data 中利用 lifespan、location、roles 等變數進行自動分組、組織計算群集、社群網絡分析、市場區隔以及天文資料分析。
Non-clustering
Non-clustering algorithm 是另一種無監督學習的學科,又稱為 Cocktail Party Algorithm,想像我們要從派對中非常多人的聲音裡面,去截取出特定一個人的聲音,聽起來要在 C++、Java 平台上實作出來非常困難,但其實只要在 Octave 環境下用一行程式碼即可達成 (得利於前人的智慧)。
[W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
因此我們應該保有一個觀念:在將學習演算法實作於專案時,應先在 Matlab、Octave 等 IDE 中快速實作,等到運行一切順利時,再回到 C++、Java、Python 等程式語言來實作同一個學習演算法,這會使得開發更加的快速與順利。