SLAM (Simultaneous localization and mapping) 問題可以分為前端 (Prediction, Tracking, Mapping) 以及後端 (Filter-based, Graph-based)。SLAM 問題的目標是在不知道自己位置的情況下,能夠做到同時定位自己並且建構地圖。
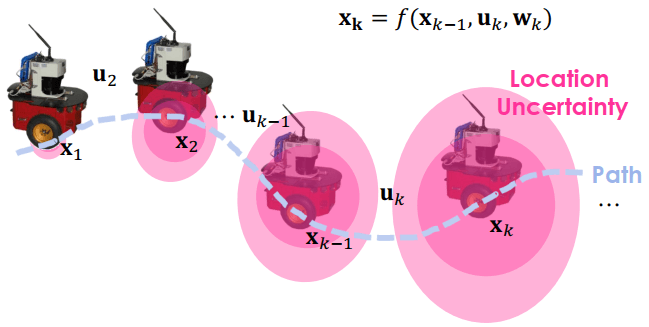
以下是自走車在不同時間 (tk) 移動到不同的位置 (xk)
- 自走車會透過控制指令 (uk) 進行移動
- 當中也會有一些誤差 (wk)
 SLAM
SLAM所以我們可以把移動到新位置的公式寫作 xk=f(xk−1,ukwk)
- 下一個位置 (xk) 等於以下三者一起計算出來的
- 前一個位置 (xk−1)
- 控制指令 (uk)
- 移動的 noise (wk)
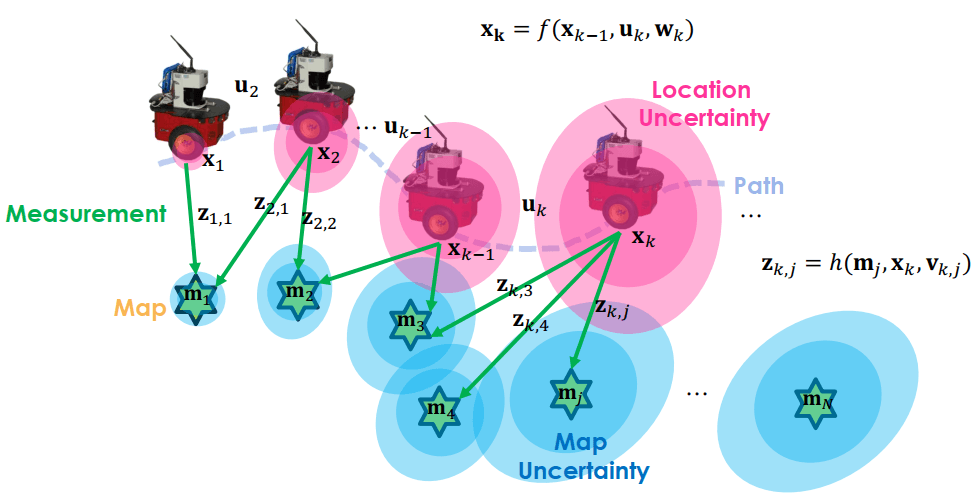
自走車行走中,同時也會用 sensor 來感測周圍的標的物 (mj),計算測量值 (zk,j)
 SLAM
SLAM在時間 k 測量目標 j 的結果可以寫成 zk,j=h(mj,xk,vk,j)
- 在時間 k 對目標 j 測量的值 (zk,j) 等於以下三者所計算出來的
- 目標物 (mj)
- 車子位置 (xk)
- 測量的 noise (vk,j)
可以看到 localize 和 mapping 都會有誤差,分別是 wk 和 vk,j
- wk 造成粉紅色的 location uncertainty
- vk,j 造成藍色的 map uncertainty
而 SLAM 問題就是如何利用帶有這些 noise 的資料,也就是 u 和 z,來估計自走車狀態 (x)、和目標物狀態 (m)
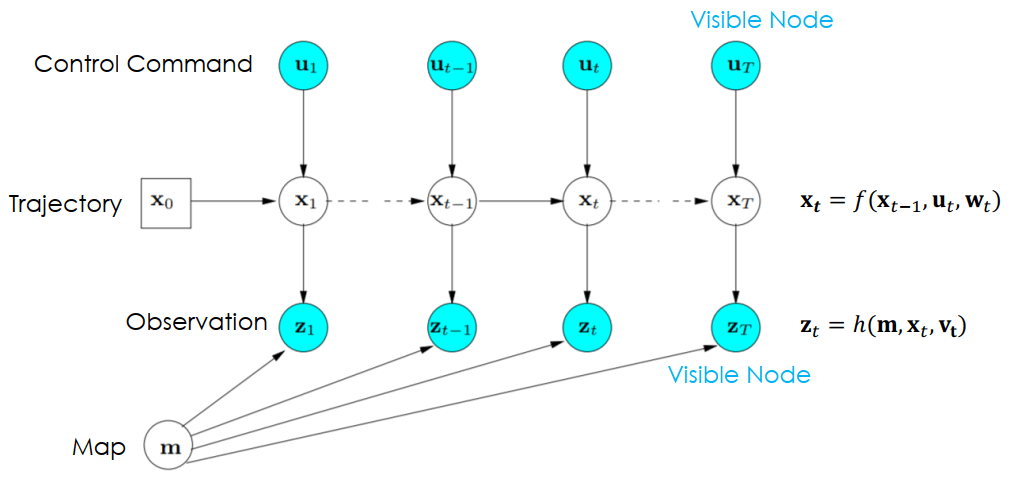
我們可以將 SLAM problem 轉為 probability graphical model 的樣式
 SLAM Probability Graphical Model
SLAM Probability Graphical Model- 每個變數變成了一個節點
- 藍色節點為 visible node 代表可以直接被偵測
- 箭頭代表了因果的關係
- Noise (wt,vt) 被自動 model 在這個機率模型裡面
可以看到在 SLAM problem 的兩個式子都可以在圖上被表現出來
xt=f(xt−1,ut,wt)zt=h(m,xt,vt) SLAM 有三個前端架構,結合在一起可以在特定時間 t 建立車子的位置 (pose, xt) 和環境的地圖 (m)。若感測器為視覺感測器,那麼 front-end 又稱 visual odometry。
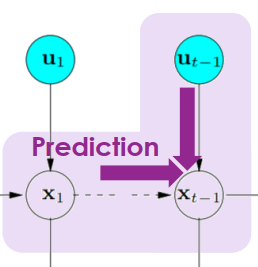
- Prediction
- 從前一刻的 xt−1 還有同時刻的 ut 來推測該時刻的 xt
 SLAM Prediction
SLAM Prediction- Tracking
- 根據目前觀測資訊 zt 來推測目前的位置狀態 xt
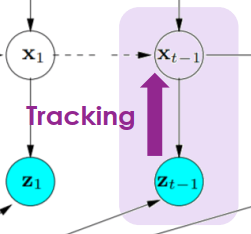 SLAM Tracking
SLAM Tracking- Mapping
- 根據目前觀測資訊 zt 來建構地圖 m
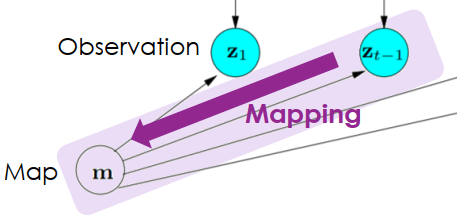 SLAM Mapping
SLAM Mapping上面的觀測、預測通常會有誤差,累積後會產生錯誤,所以需要由 back-end 來修飾。在 back-end 有兩種做法來補償誤差,一種是 filter-based 一種是 graph-based。
- Filter-based error compensation
- 直接根據最近的誤差來調整
- 即時 (online) 但整體優化不佳
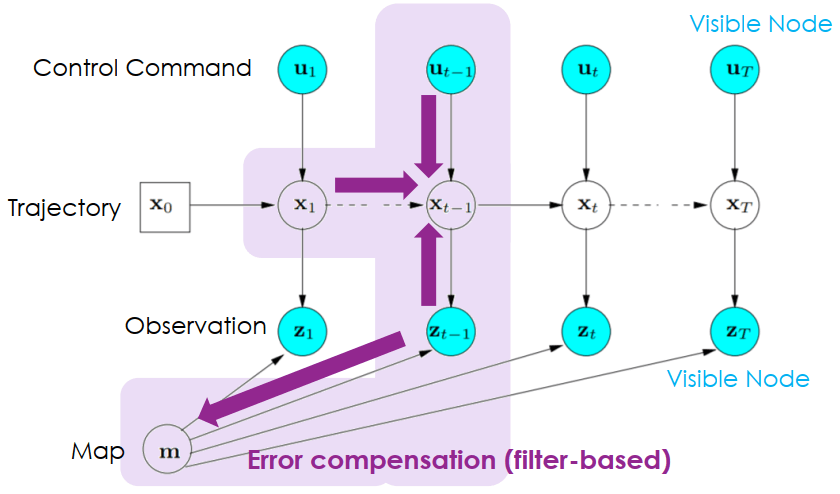 SLAM Filter-based Error Compensation
SLAM Filter-based Error Compensation- Graph-based error compensation
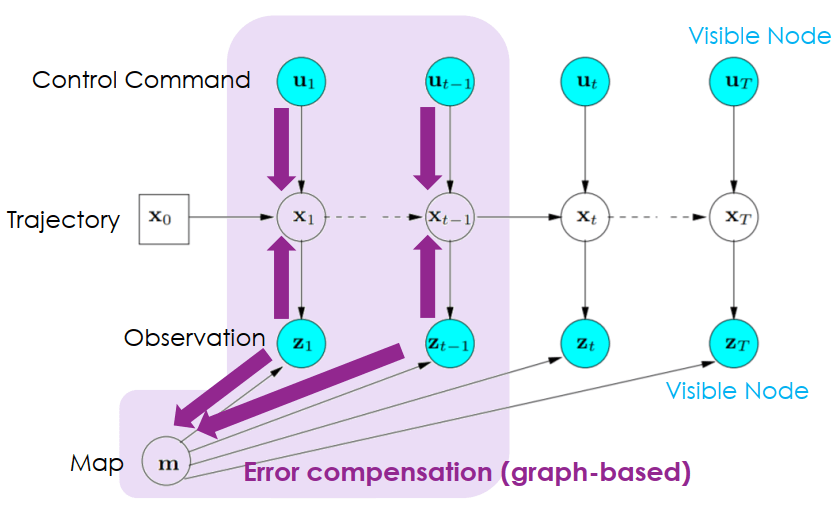 SLAM Graph-based Error Compensation
SLAM Graph-based Error Compensation發現 error 的方法稱為 loop closure detection
- 檢查自走車是否到達以前到過的位置
- 確定繞一圈後,將資訊丟給 error compensation
Inference 是從 premises 來推測出 consequences 的過程,因為不可能從所有 premises 來推測,所以只拿一些 samples 來測,叫做 statistical inference。
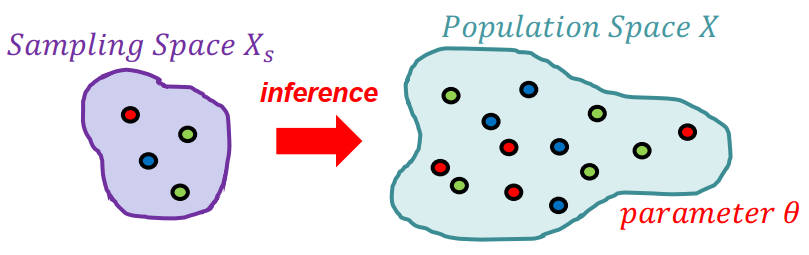 Statistical Inference
Statistical Inference- Hypothesis Testing (Top-down)
- 是機器學習常用作法
- 透過不斷假設 parameters 並帶入 samples 來評估結果是否正確
- 最終得到最棒的 parameters
- Estimation (Bottom-up)
- 直接從 samples 去推測 parameters
最有名的 estimation 是 MLE。MLE 看哪一個參數 (θk) 的 likelihood 分布最有可能產生 samples (x)。
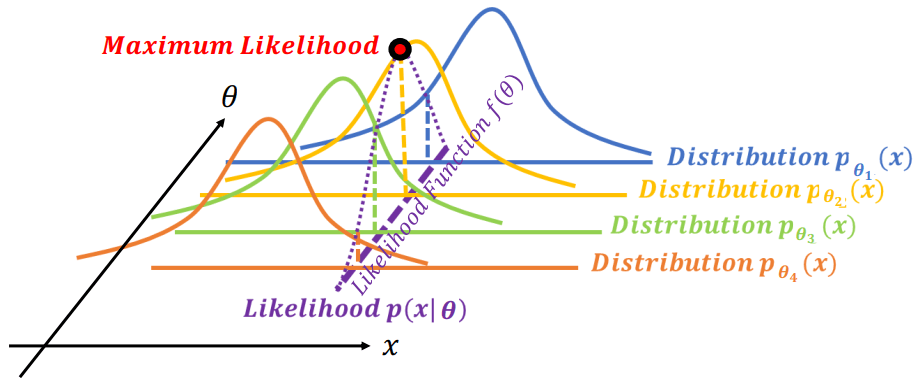 Maximum Likelihood Estimation
Maximum Likelihood Estimation可以看到在不同 θ 分布下產生 x 的機率為 likelihood (p(x∣θ)),而所有不同參數 p(x∣θ) 所連成的線就是 likelihood function (f(θ))
Maximum a Posteriori Estimation
MLE 採樣時可能產生誤差,猜錯真正的 likelihood 分布,所以有了 MAP。MAP 多考量了 prior 的機率,所以可以降低 MLE 採樣錯誤所產生的誤差。
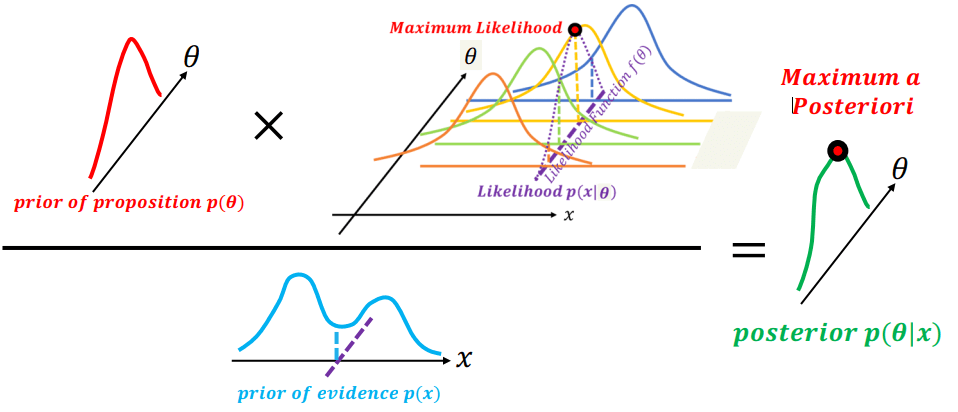 Maximum a Posteriori Estimation
Maximum a Posteriori Estimation以投硬幣舉例,總共投了五次 (Tail, Tail, Tail, Head, Tail),我們想知道正面機率 (θ) 是多少,才造成上面的結果 (x),也就是要求 likelihood (p(x∣θ))。
Find pmaxθ(1−θ)4dθdθ(1−θ)4=(1−θ)4+4θ(1−θ)3(−1)=(1−θ)3(5θ−1)=0θ=0.2 同樣的題目,我們定義 prior 為 Discrete Uniform Distribution,也就是各為 1/11 (0.0 到 1.0)
p(x)p(θ)p(x∣θ)=p(θ∣x)
p(x)=∑θp(x,θ)=∑θp(x∣θ)p(θ)⎣⎡1/111/111/11⋮⎦⎤×⎣⎡(0)1(1)4(0.1)1(0.9)4(0.2)1(0.8)4⋮⎦⎤=⎣⎡0.0000.2130.333⋮⎦⎤ 因為 prior 是 uniform distribution,所以其實 MAP 沒有改變太多
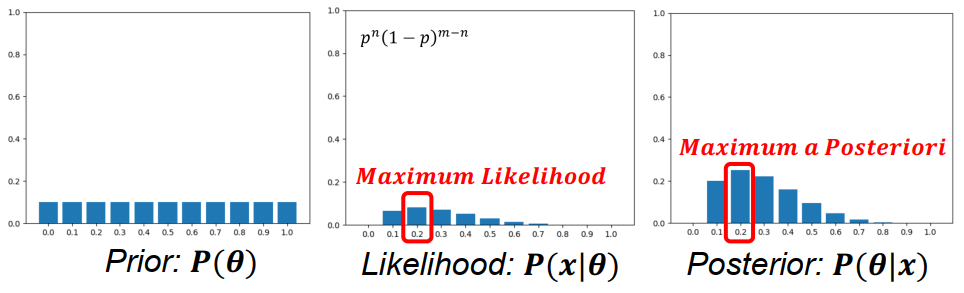 MLE vs MAP
MLE vs MAP不斷用 prior + likelihood 來計算 posterior 並更新假設
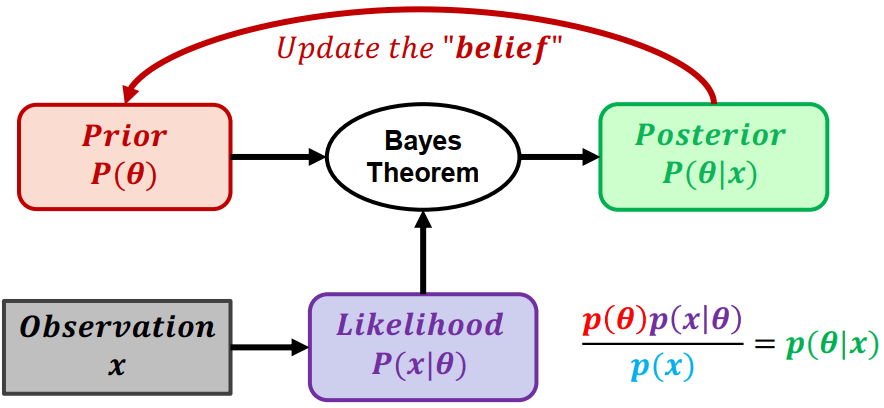 Bayesian Approach
Bayesian Approach不再是看誰讓 likelihood 或 posterior 最大化,而是直接觀察 parameters 的分布
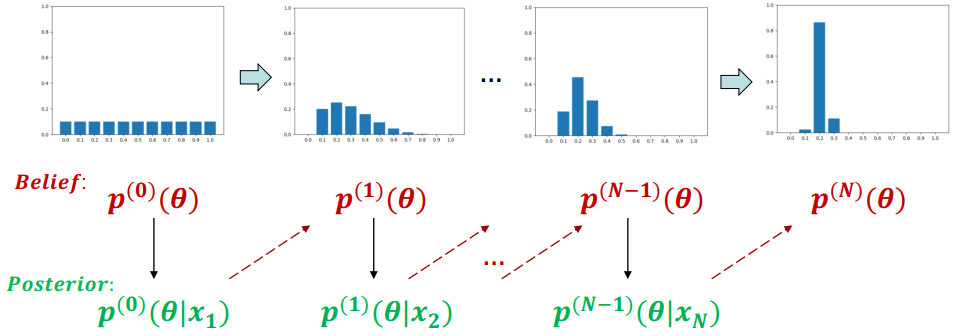 Bayesian Approach Example
Bayesian Approach ExampleBayesian approach 會將參數 (θ) 帶入 prior、likelihood 計算出 posterior。posterior 再重新做為下一輪的 belief 進行計算,最終找出參數 (θ) 的分布
我們也可以應用於 SLAM 的 probability graphical model
P(xt∣z1:t−1,u1:t)=∫P(xt∣xt−1,z1:t−1,u1:t)P(xt−1∣z1:t−1,u1:t)dxt−1=∫P(xt∣xt−1,ut)P(xt−1∣z1:t−1,u1:t)dxt−1 - 我們可以用 u1 到 ut
- 以及 z1 到 zt
- 來估算當前時間點的 xt
化簡中,因為 xt−1 為已知,所以 xt−1 之前的觀測資訊就都不重要了。
我們可以將式子簡寫成以下樣子 (bel 代表 belief)
bel(xt)=∫P(xt∣xt−1,ut)bel(xt)dxt−1 - bel(xt) 為當下時刻的估測
- 當下時刻還沒觀測到同時間的 zt
- bel(xt) 為前一時刻的估測
- 已經觀測到該時間點的 tt−1
當我們得到了觀測資訊 (zt) 就可以用來更新位置資訊 (xt)
P(xt∣z1:t,u1:t)=P(zt∣z1:t−1,u1:t)P(zt∣xt,z1:t−1,u1:t)P(xt∣z1:t−1,u1:t)=ηP(zt∣xt,z1:t−1,u1:t)P(xt∣z1:t−1,u1:t)=ηP(zt∣xt)P(xt∣z1:t−1,u1:t) - 可以看到左邊的算式中有 z1:t
- 但右邊的只有 z1:t−1
一樣可以轉成以下的 belief 表達方式
bel(xt)=ηP(zt∣xt)bel(xt) - bel 表示有 zt 資訊
- bel 表示沒有 zt 資訊
Bayes filter 就是上面兩個式子遞迴互相更新所產生
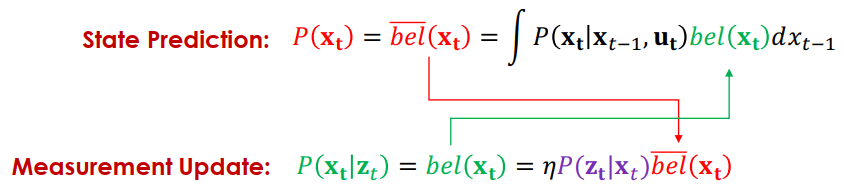 Bayes Filter Algorithm
Bayes Filter Algorithm寫成 pseudo code 表示為
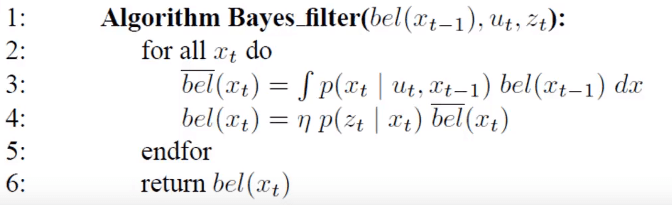 Bayes Filter Algorithm Pseudo Code
Bayes Filter Algorithm Pseudo Code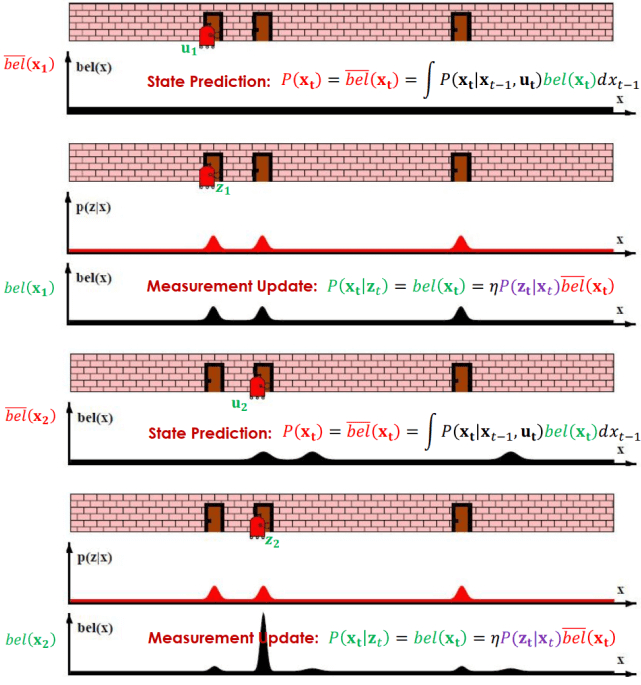 Bayes Filter Algorithm Example
Bayes Filter Algorithm Example- 一開始的 bel(xt) 是 prior distribution
- 感測到 z1 得到 likelihood (P(zt∣xt)) 後可以更新 bel(x1)
- 接著有了 u2 可以更新運動狀態 bel(x2)
- 接著一樣感測到 z2 更新回去得到最新的 bel(x2)