Shallow Neural Network
Shallow Neural Network 指的是只有幾層 (2 層或以下) 的神經網路 (Neural Network)。它們只有輸入層 (input layer) 和輸出層 (output layer),通常在中間有一層隱藏層 (hidden layer)。它們常用於一些簡單的機器學習任務,例如垃圾郵件分類,激活函數 (activation function) 通常會用 Sigmoid、Tanh 或 ReLU 來替代線性激活函數。激活函數是一種用於增強神經網路計算能力的函數,為了能夠計算 gradient descent (backpropogation),需要知道每個 activation function 的導數為何,比如 Sigmoid、Tanh、ReLU 和 Leaky ReLU,其導數可以用微分技巧來計算。此外,為了避免所有 weight 初始化全部為 0 的問題,我們會使用隨機取值來初始化 weights。
Neural Network Representation
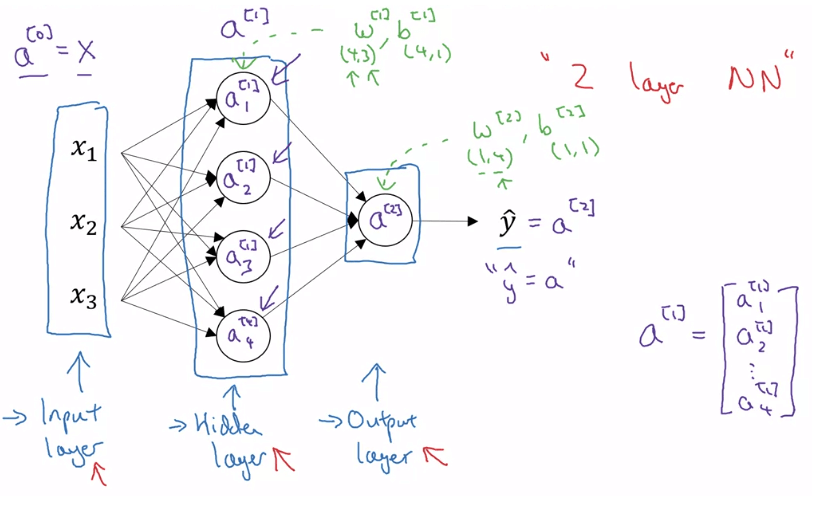
- 一個 nn 會有 input, hidden, output layer
- 因為 training set 不包含 hidden layer 的資訊所以得名
- 在說明 layer 數時,通常不會包含 input layer
- Notation
- 所有 superscript 用來表示第 layer
- 第一層的 就是
- input 會用 表示
- Notation
- 除了 input 以外,每一層都會有 這些 parameters
- parameter 的 dimension 會是 current layer nodes by parent layer nodes
- parameter 的 dimension 會是 current layer nodes by 1\
Computing a Neural Network's Output
- 一個 neuron 裡的運算可以拆成 z 和 a
- 一個 4 unit 的 layer 就要算四次 z 和四次 a
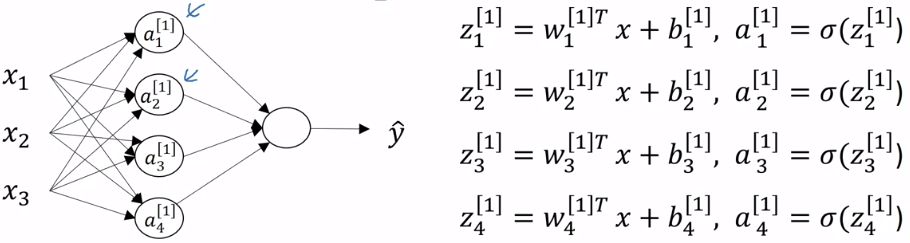
- z 和 a 的運算都可以向量化
- 裡面的 就是一個 4 * 3 的矩陣
- 另外我們可以用 來表示
- 所以計算 (forward propogation) 的運算如下
Vectorizing Across Multiple Examples
- 我們有 1 到 m 個 training examples
- 若用 for-loops 來計算每一個 example 對應的
- 裡面的 代表第 1 筆 example 的 layer 2 的 a 向量
- 我們的目標其實就是用 nx * m 的 矩陣
- 來算出 1 m 的 矩陣,再求出同樣為 1 m 的 矩陣
- 橫軸的 m 代表有 m 筆 examples
- 縱軸的 n 代表有 n 筆 hidden units
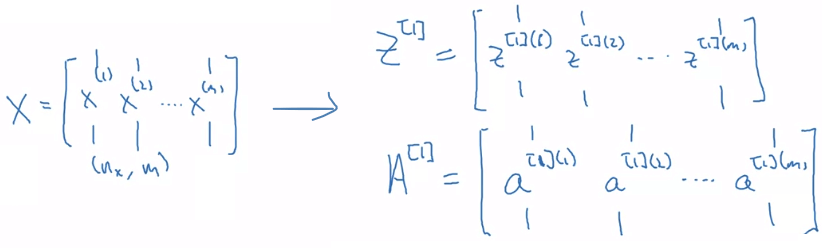
- 整個 vectorize 的 forward propogation 過程
Activation Functions
- Activation function 會影響到 gradient descent 的速度
- 例如 sigmoid 在大於或小於一定數字後 slope 就會接近 0
- 所以 sigmoid 並不是最好的 activation function
- 但 sigmoid 可以用於 logistic regression 的最後一層 output (0, 1)
- tanh 是一個可以取代 sigmoid 的選擇
- 他就是 sigmoid 的位移,區間變成 [-1, 1]
- 因為平均值變為 0 的關係,有集中 data 的效果
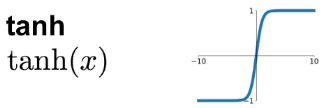
- ReLU 是現在所有人公認最好的 activation function
- 如果你不知道該用什麼在 hidden layer,用 ReLU 就對了
- 他解決了 sigmoid 在一些數字越大時,slope 越小的問題
- 雖然在負數時,導數皆為 0,但是是沒問題的
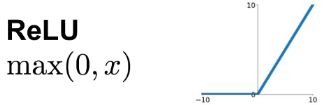
- Leaky ReLU 是 ReLU 的變形
- 修正了負數導數為 0 的問題
- 但一般來說,使用 ReLU 就夠了

Why Non-linear Activation Functions
- 若你把某一層 hidden layer 的 activation function 全部取消掉
- 輸入會永遠等於輸出,這稱為 linear activation function
- 若使用 linear activation function 則該層的運算會跟沒算一樣
- hidden layer 有跟沒有一樣
- 甚至在所有 hidden 使用 linear,而最後一層使用 sigmoid 時
- 算出來的效果比 logistic regression 還要差
Derivatives of Activation Functions
- 為了能夠計算 gradient descent (backpropogation),需要知道每個 activation function 的導數為何
- Sigmoid 為
- 他的導數如下,需要用到一些微分技巧
- 他的導數如下,需要用到一些微分技巧
- Tanh 為
- 他的導數如下,一樣需要用到微分技巧
- 在 nn 中我們會以 表示,所以微分也可寫成以下
- 他的導數如下,一樣需要用到微分技巧
- ReLU 為
- 他的導數如下
- 當 時雖然為 undefined,但在電腦中可以自行決定要等於 0 或 1
- 其實沒有太大影響
- 他的導數如下
- Leaky ReLU 為
- 他的導數如下
- 他的導數如下
Gradient Descent for Neural Networks
- 假設有一個 2-layer nn
- input, hidden, output units 的數量,分別為
- Parameters 有
- 然後 Cost Function 為
- 所以 Gradient Descent 大致上運作如下
- 接著我們要深入一點,在公式中解出 這些導數
- 以下是一個已經 vectorized 的 backpropogation formula
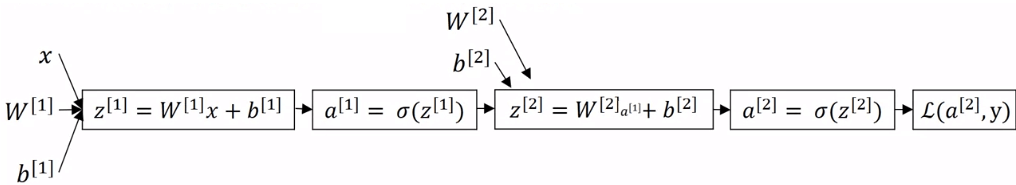
- 第四行的 是怎麼來的
- 我們可以寫成 chain rule
- 紅色部份就是
- 綠色部份就是 的導數,等於
- 最後藍色部份是 的導數,等於
Random Initialization
- 在 machine learning 中提過,若 初始全為 0
- 會讓整個 layer 全部都做一樣的事情
- 所以在初始化 nn 的 weights 時,會使用隨機取值
- b 可以初始為 0 沒關係
- 以下是用 python 進行 random initialization 的動作
w1 = np.random.randn(2, 2) * 0.01
b1 = np.zeros(2, 1)
w2 = ...
b2 = ...
...