本文介紹了有助於進行深度學習最佳化的算法,包括 Mini-Batch Gradient Descent 以及 Exponentially Weighted Averages。因為 Batch Gradient Descent 對整個 training set 進行一次 gradient descent,每個 iteration 時間較長,訓練過程較慢。Mini-Batch 將 Batch 和 Stochastic Gradient Descent 優點合併,但需要找出適合的 batch size。Exponentially Weighted Averages 是一個用於分析移動平均的算法,可以減緩短期波動,反映長期趨勢。
另外本文還介紹了一些優化 Gradient Descent 的算法,包括 Momentum、RMSprop 和 Adam,並介紹了如何應用學習率衰減的技術,以及深度學習中的局部極值和鞍點問題。
- 當 training set 非常大,例如有 m = 5000000 筆時
- Batch gradient descent 需要跑完所有 m 才能進行一次下降
- Mini-batch gradient descent 從 m 中取出一批一批 training set
- 假設每 1000 筆一批
- 那就可以執行 5000 次下降
- 全部 5000 筆執行完一次,稱為 1 epoch
- 前 1000 筆用 (X{1},Y{1}) 表示,
- 最後 1000 筆就是 (X{5000},Y{5000})
- 每次執行的 gradient descent 和 batch 時一模一樣
- 執行 5000 次完還可以重複進行,直到 converge
- Batch 和 Mini-Batch 的 cost per iteration 如下
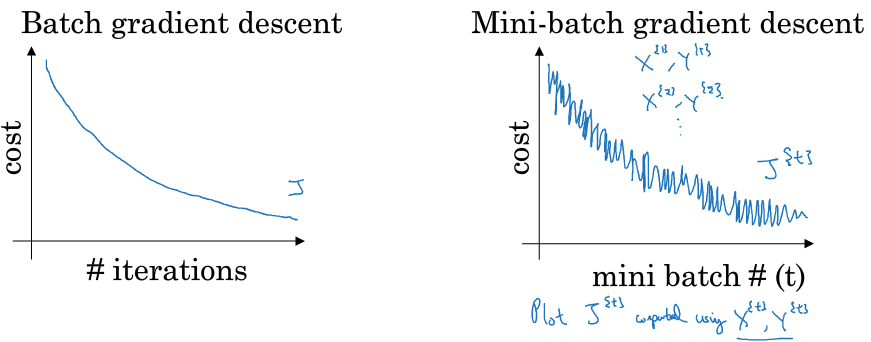 Batch vs Mini-Batch
Batch vs Mini-Batch- Mini-batch size 也是一個需要經驗的 hyperparameter
- 當 size = m 時
- 就是原本的 Batch gradient descent
- 當 size = 1 時
- 稱為 Stochastic gradient descent
- 每讀一筆 training set 就做一次 gradient descent
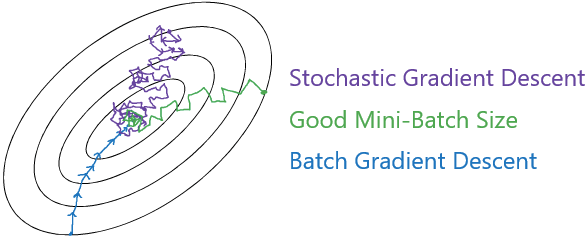 Batch size comparison
Batch size comparison- Batch Gradient Descent
- 對整個 m 進行一次 gradient descent
- 下降幅度較大,很穩定往最小值移動
- 每個 iteration 時間很長,訓練過程很慢
- Stochastic Gradient Descent
- 速度很快
- 但完全沒享受到 vectorization 的加速優勢
- 永遠不會 converge,會在最小值周圍移動
- 可以用 learning rate decay 解決
- Mini-Batch
- 將兩者優點合併,但需要找出適合的 batch size
- 若 m 較小,如 m≤2000 可以考慮直接使用 batch gradient descent
- 若 m 較大,通常使用 26,27,28,29 作為 batch size 較好
- 符合電腦 memory 儲存方式
- 另外,size 一定要定義為 CPU/GPU 裝的下的大小
- 在實作一些比 gradient descent 還要棒的 optimization algorithm 前
- 需要先學會使用 Exponentially Weighted Averages
- 這是一種用於分析移動平均的算法、像天氣、股票等一連串資訊
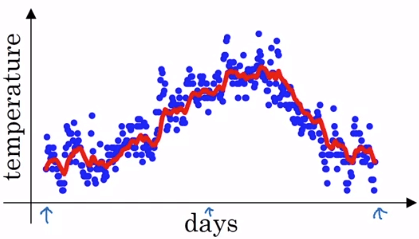 Exponentially Weighted Averages
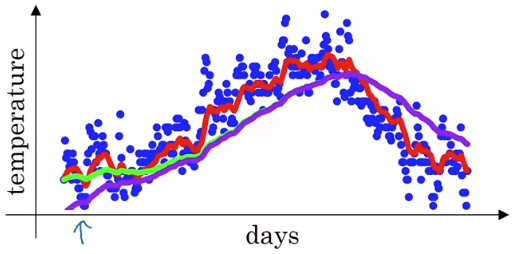
Exponentially Weighted Averages- 例如上圖是倫敦一整年的溫度變化圖
- 我們想算出他的移動平均 (紅線)
- 我們定義 vi 為前一天算完的平均 (v0=0)
- 定義 θi 為每一天的溫度
- 我們可以用以下算法算出紅線
v0v1v2⋮v365=0=0.9v0+0.1θ1=0.9v1+0.1θ2=0.9v364+0.1θ365 - 可以將以上循環定義為一個簡單公式
- 把 vt 想成是 ≈1−β1 天的溫度
vt=βvt−1+(1−β)θt - 所以 β 是一個 weight,在上面例子是 0.9
- 若設定 β=0.98
- 設定 β=0.5
- 所以 β 越小,代表平均越少前面天數,就會改變的越激烈
- 所以綠線就是平均前 50 天所產生的線 (β=0.98)
- 黃線則是平均前 2 天 (β=0.5)
- 我們這目標是在不同分析中找到類似紅色的線
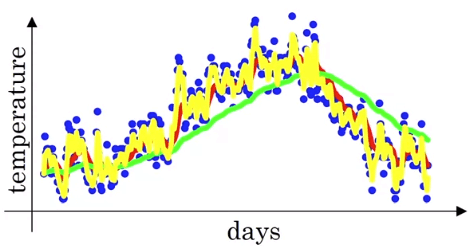 Exponentially Weighted Averages
Exponentially Weighted Averages- 我們設定 β=0.9,可以計算出
⋮v98v99v100=0.9v97+0.1θ98=0.9v98+0.1θ99=0.9v99+0.1θ100 - 然後把計算到 v100 的值攤開
v100=0.1θ100+0.1×0.9θ99+0.9v98=0.1θ100+0.1×0.9θ99+0.1×0.92θ98+0.9v97=⋯ - 因為每個 θi 代表第 i 天的真實溫度
- 每個 θi 前方的 0.1×0.9(n−i) 稱為 Bias correction
- 所有的 Bias correction 加總會接近或等於 1
- 而真實溫度會隨著 Bias correction 不斷被降低 (被無視)
β→0lim(1−β)β1=e1≈0.368 Repeat : v:=βv+(1−β)θt - 雖然不會比你直接計算前 10 天、50 天的平均還要精準
- 但他只需要一行代碼、而且佔用非常少 memory、效率極高
 Bias Correction Adjustment
Bias Correction Adjustment- 實際上會因為 vt 從 0 開始
- 所以 v1=βv0+(1−β)θ1
- 前項完全被消掉,因此第一個 v 僅為當天溫度的 (1−β) 倍
- 會產生紫色線一樣慢熱的狀況
- 我們可以修改 vt 為以下公式
vt=1−βtβvt−1+(1−β)θt - 這個修正讓 v 在一開始可以正常一點
- 而隨著 t 越大,βt 將趨近於 0,代表整個修正不再影響結果
- Momentum 事實上就是對 gradient 進行 Exponentially weighted averages 的計算
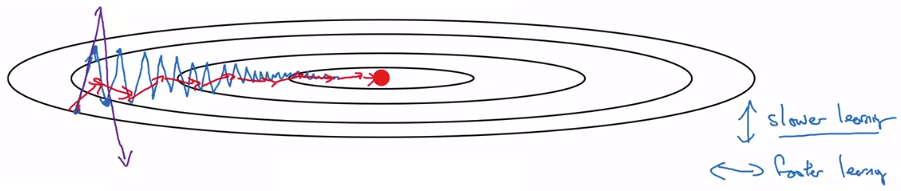 Gradient Descent with Momentum
Gradient Descent with Momentum- 上面用一個 intuition 解釋
- 藍線為一般的 gradient descent
- 紫線為 learning rate α 特別大的 gradient descent
- oscillation 更大,甚至會 overshoot
- 我們的目的就是要減少上下擺動的幅度
- 所以 gradient descent with momentum 的實作如下
On iteration t :Compute dw,db on current mini-batchvdW=β(vdW)+(1−β)dWvdb=β(vdb)+(1−β)dbW=W−α(vdW)b=b−α(vdb) - 其中 vdW,vdb 就是計算 exponentially weighted averages 的方法
- 而 β 跟 α 一樣,是一個 hyperparameter
- 當 β=0,就等於一般的 gradient descent
- 通常會設置 β=0.9,會很好的得到紅線的效果
- momentum 不需要修正 bias correction
- RMSprop 全名為 Root-Mean-Square Propagation
- 我們假設 w 和 b 是主要影響 oscillation 的 parameters
- 而 b 是影響上下擺動較嚴重的 parameter
 RMSprop
RMSprop- 我們先來計算 RMSprop
- 為了跟 momentum 區分,RMSprop 中的 β 改為 β2
On iteration t :Compute dw,db on current mini-batchsdW=β2(sdW)+(1−β2)(dW)2sdb=β2(sdb)+(1−β2)(db)2W=W−αsdW+ϵdwb=b−αsdb+ϵdb - 因為 W 較小,所以用 (dW)2 計算的 sdW 也會較小
- 那麼更新 W 時,sdW 在分母,算出來的 dw 就適中
- 而 b 較大,所以用 (db)2 計算的 sdb 就會較大
- 那麼更新 b 時,sdb 在分母較大,算出來的 db 就會變小
- 就可以抑制上下的 osciilation
- 另外在分母加上 ϵ,是為了防止分母太小,導致數值不穩定
- 這裡只是舉 b 為影響上下擺動嚴重的 parameter
- 實際例子可能為 w1,w2,w3,⋯ 是影響上下擺動的原因
- 而 w4,w5,⋯ 是不影響的
- β2 也是一個 hyperparameter
- Adam 的全名為 Adaptive Moment Estimation
- Adam 將 momentum 和 RMSprop 融合在一起,得到更好效果
- 以下是 Adam 算法
- 初始化以下參數
vdW=0,vdb=0,sdW=0,sdb=0
- 在每個 iteration t 進行計算
- 在 momentum 部分的 β 用 β1 表示
- 在 RMSprop 部分的 β 用 β2 表示
Compute dw,db on current mini-batchvdW=β1(vdW)+(1−β1)dWvdb=β1(vdb)+(1−β1)dbsdW=β2(sdW)+(1−β2)(dW)2sdb=β2(sdb)+(1−β2)(db)2 - 接著在 Adam,要對這四個參數進行 bias correction adjustment
vdWcorrectedvdbcorrectedsdWcorrectedsdbcorrected=1−β1tvdW=1−β1tvdb=1−β2tsdW=1−β2tsdb - 最終更新參數 w,b
Wb=W−αsdWcorrected+ϵvdWcorrected=b−αsdbcorrected+ϵvdbcorrected - 以上就是整個 Adam 算法
- 在這個算法中出現非常多 hyperparameters
- α : learning rate,需要自己慢慢找到一個合適的
- β1 : momentum 使用到的像 exponentially weighted averages 的 weight
- β2 : RMSprop 所使用到的 β,一樣是由 exponentially weighted averages 而來
- ϵ : 不重要,用預設的 10e-8 即可
- β1,β2,ϵ 通常不太需要去修改調整
- 若使用固定 α 的 mini-batch,那麼 gradient descent 幾乎不會準確 converge
- gradient descent 將會在最小值周圍擺動
- 為此我們可以讓 α 隨著時間慢慢減少
- 一開始 α 較大,幫助我們跨大步伐
- 最終 α 變小,幫助我們在最小值收斂
- 最常用的 learning rate decay 公式如下
α=1+decay-rate×epoch-num1×α0 - α0 是初始的 learning rate
k epoch 代表所有 mini-batch 全跑過 k 遍decay-rate 是一個 hyperparameter
- 假設我們設計 α0=0.2,decay-rate = 1
- 那 α 將會隨著跑過所有 mini-batch 的次數而下降
| Epoch | α |
|---|
| 1 | 0.1 |
| 2 | 0.067 |
| 3 | 0.05 |
| 4 | 0.04 |
| ... | ... |
- Exponentially Decay
- α=0.95epoch-num×α0
- α=epoch-numconstant×α0
- α=mini-batch-num tconstant×α0
- Discrete staircase
- Manual decay : Only small num training set
- 在 machine learning 時,我們對梯度接近 0 的想像都是 local optima
- 但在 deep learning 中,你的維度變的非常大
- 通常會遇到梯度接近 0 的地方是 saddle point
- 所以在大型的 nn、有著大量參數、較高維度時
- 困在 local optima 的情況是不太可能的
- 所以 deep learning optimization 的問題不是 local optima 而是 plateaus
- 這個 saddle point 或者 plateaus 會使得 learning 速度變慢
- 所以才會不斷的推出新的 optimization algorithm
- Momentum, RMSprop, Adam, ...
- 這些算法能夠加速離開這些梯度接近 0 的點
- 甚至找出更棒的 optimization algorithm 是 deep learning 的挑戰之一
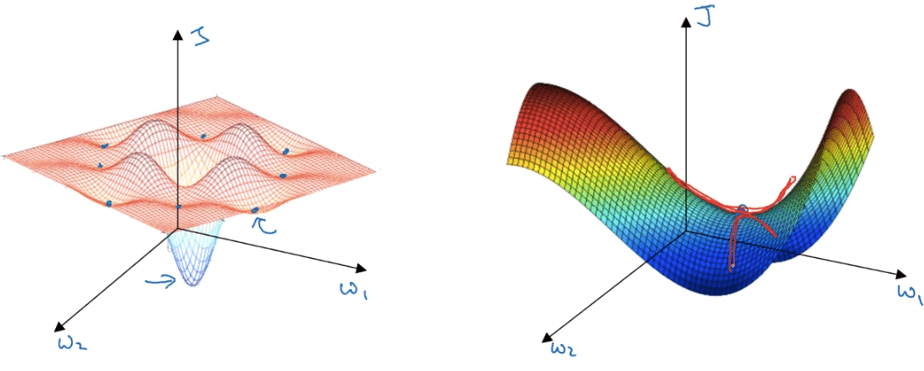 Local Optima and Saddle Point
Local Optima and Saddle Point