Classification and Representation
Logistic regression 是一種分類器,它可以適用於 binary classification problem,也就是只有兩種結果的問題。它也可以用來表示一個事件發生的可能性,我們可以用它來預測出結果是 0 或 1 的機率。
Logistic regression 包含了兩個重要的概念: hypothesis representation 和 decision boundary。hypothesis representation 就是用 logistic function 來表示 hypothesis 的方式,而 decision boundary 就是用來區分 0 和 1 的線。此外,我們也可以使用 linear 和 non-linear 的方式來表示 decision boundary。
- 舉幾個簡單的例子
- Email : Spam / Not spam
- Transaction : Fraud / No fraud
- Tumor : Malignant / Benign
- 我們會用 0/1 來代表結果
- 0 = Negative class
- 1 = Positive class (通常為計算中比較想知道的結果)
- 例如 :
y∈{0,1}∣ 0 = benign tumor, 1 = malignant tumor - 當然 classification 可以有多種結果
- 但現在只專注在 binary classification problem
- 我們可以利用 linear regression 來找到 Hypothesis
- 只要簡單的設置一個 threshold (例如 0.5)
y < 0.5 的是 0 而 y > 0.5 的是 1
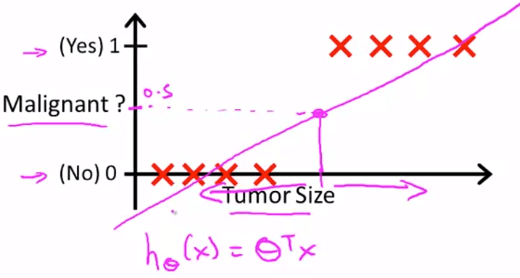 Linear Regression Classification
Linear Regression Classification- 但這方法不好,假設今天有一個 outlier 出現在 plot 的最右方
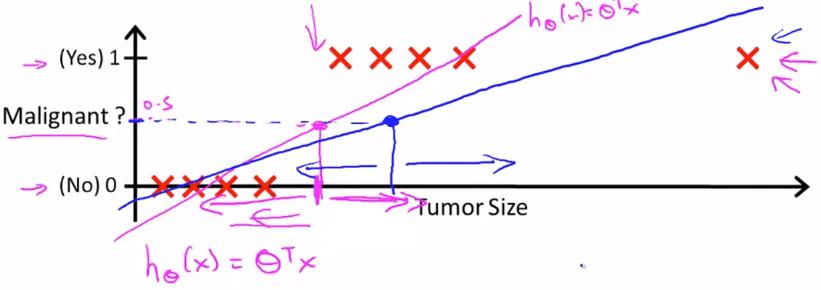 Linear Regression Classification Fail
Linear Regression Classification Fail另外,若使用 linear regression 來預測 hypothesis 時
hθ(x) can be >1 or <0 所以我們在解決 classification problem 時
會使用 Logistic Regression,他會使得 h 的區間在合理範圍
0≤hθ(x)≤1 所以在解決 classification problem 時
我們的 hypothesis 將套用 Logistic Function g (又稱作 Sigmoid Function)
g(z)=1+e−z1 Logistic function 的長相像這樣
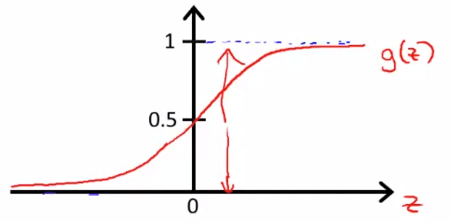 Logistic Function Graph
Logistic Function Graph不超過 0 和 1 的 boundary,而且看起來很適合處理 classification
所以我們將他套入原本的 hypothesis :
hθ(x)=g(θTx)=1+e−θTx1 現在 hypothesis 有了全新的意義
hypothesis 現在代表 1 出現的 Probability
也就是 positive class 的出現機率
用機率的方法表示如下 :
hθ(x)=P(y=1∣x;θ)=1−P(y=0∣x;θ) or P(y=0∣x;θ)+P(y=1∣x;θ)=1 用 tumor 的例子來說 :
if hθ(x)=0.7then the tumor have 70% to be 1 (malignant).and the tumor have 30% to be 0 (benign). 為了更好的辨識 0/1
我們以 0.5 作為間隔值
也就是說大於等於 0.5 的都是 1,而小於 0.5 的是 0
hθ(x)≥0.5→y=1hθ(x)<0.5→y=0 另外我們觀察到 sigmoid function
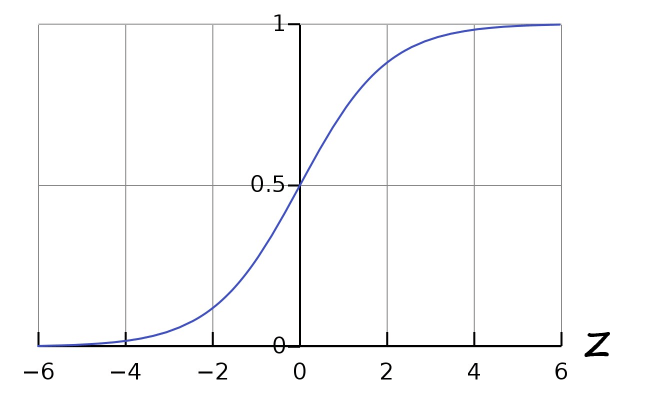 Sigmoid Function
Sigmoid Function只要 y > 0.5 那 z 就一定大於 0
若 y < 0.5 那 z 就一定小於 0
z=0,g(z)=1+e−01=21z→∞,g(z)=1+e−∞1=1z→−∞,g(z)=1+e∞1=0 因此我們可以推測出 :
g(z)≥0.5when z≥0hθ(x)=g(θTx)≥0.5when θTx≥0 現在我們只要看 θTx 就可以判斷 :
θTx≥0⇒y=1θTx<0⇒y=0 而介於兩者中間的那一條線,就是 Decision Boundary
假設我們已經知道下方 training sets 的 hypothesis 了
(會在之後的篇幅講到如何找到 hypothesis)
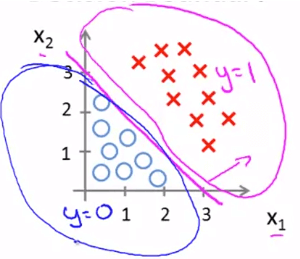 Decision Boundary
Decision Boundaryhθ(x)=g(θ0+θ1x1+θ2x2),θ=⎣⎡−311⎦⎤ 將 θ 代回 hypothesis 可以得到
−3+x1+x2≥0⇒y=1x1+x2≥3⇒y=1x1+x2<3⇒y=0 而x1+x2=3
就是分割兩群 data set 的 decision boundary
在 classification problem 中我們也可以沿用 linear regression 的技巧
使用 quadratic, cubic 等不同 function 來表示 hypothesis
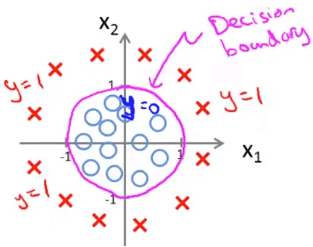 Decision Boundary
Decision Boundary例如上面這種類型的 training sets
Hypothesis 為
hθ(x)θ=g(θ0+θ1x1+θ2x2+θ3x12+θ4x22)=⎣⎡−10011⎦⎤ 所以
−1+x12+x22≥x12+x22≥01⇒y=1 我們就可以知道 decision boundary 為 :
x12+x22=1 也就是圈起來的那條線