Introduction of Neural Networks
神經網路是為了模擬人類的大腦運作,大腦可以透過一種 learning algorithm 做到聽、說、讀、寫等活動,而神經網路的最小單位為神經元,它可以由 input wires 接收多個輸入,並將處理過的訊息傳送出去透過 output wires。我們可以再加上 bias unit 作為輸入,而處理這些 input 的為 sigmoid (logistic) activation function。當有多層 layer 時,第一層為 input layer,最後一層為 output layer,而中間所有的層統稱為 hidden layer。我們給予 hidden layer 的 nodes 一個名字:activation units,它是經由 input 和 matrix of weights 作用 output 過來的,hypothesis 就是這些 activation units 經由權重矩陣與輸入矩陣相乘後的結果。
 Motivation of Neural Networks
Motivation of Neural Networks想像我們為了解決上面這個 Non-linear classification
必須使用 sigmoid function 搭配很多的 parameters 和新 features
g(θ0+θ1x1+θ2x2+θ3x1x2+θ4x12x2+θ5x13x2+θ6x1x22+⋯) 像上面用了兩個 features 就產生了可能 "Overfitting" 的 hypothesis
當我們有更多的 features 時,新 features 的數量將以指數成長
當我們要用機器學習來辨識圖片時 (舉例: 車子)
我們將整張圖片的每一個 pixel 截取出來,並給予 intensity (0-255 灰階)
我們將不同圖片的 pixel 資訊 plot 在一個二維空間中,用以分辨該 pixel 為多少時是否為車子
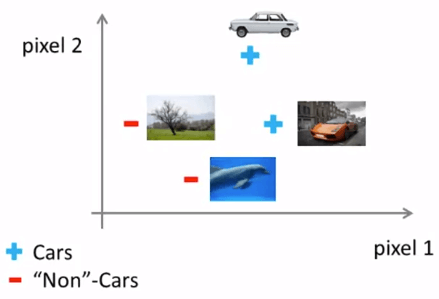 Computer Vision Classification
Computer Vision Classification這種時候就可以用到 non-linear hypothesis
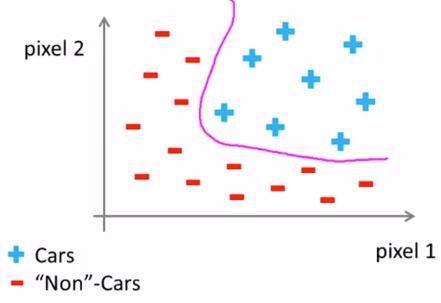 Computer Vision Classification
Computer Vision Classification假設我們只要辨識 50 * 50 pixel 的小圖片
那我們將會用到 2500 的 features (7500 if RGB)
而產生的新 features 將會達到約 3 billion features
一開始 neural networks 是為了試圖模擬人的大腦運作
大腦可以讓我們做幾乎任何事情,聽、說、讀、寫、看、觸 ...
而其實大腦只花了一種 learning algorithm 就做到這些事情
科學家用一種 Neural Rewiring 的實驗發現了這件事情
他們將動物接收聽覺的 Auditory Cortex REWIRE 接收視覺
他們發現 Auditory Cortex 變得能夠接收到視覺
還有許多將 Sensor 與大腦結合的發明
這些東西告訴我們
其實大腦只用了一種 algorithm 來教導身體做事
而我們的最終目標就是找到這個 learning algorithm 的 hypothesis
並且把他運用在電腦上
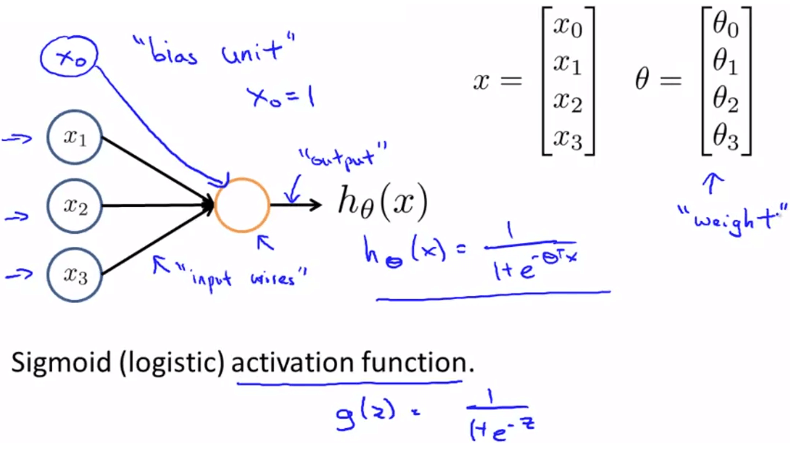
Neuron 作為 neural networks 的最小單位,模擬人類的神經元
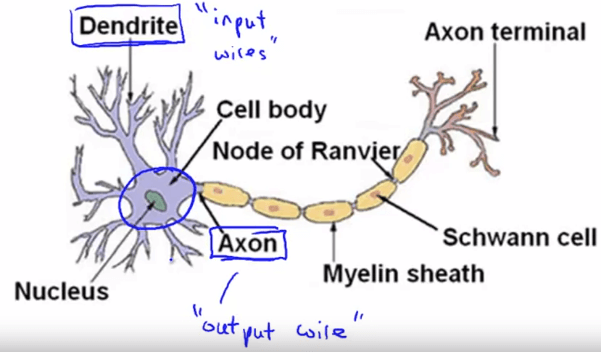 Neuron in Human
Neuron in Human- 透過 input wires (dendrites) 接收多個 input
- 並從 output wires (axons) 將處理過的訊息傳送出去
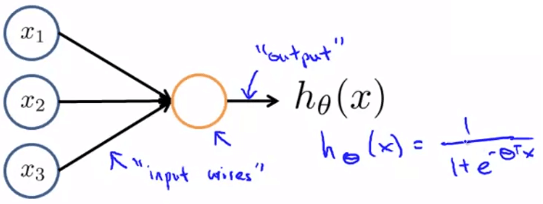 Neuron in AI
Neuron in AI其中 input 的是 features x1,x2,⋯xn
而 output 就是 hypothesis function hθ(x)
我們會在 input 再加上一個 x0 作為 bias unit 永遠為 1
而處理這些 input 的為 sigmoid (logistic) activation function 1+e−θTx1
而在 neural networks 中 θ 這個 parameters 又稱作 "weight"
 Neuron in AI
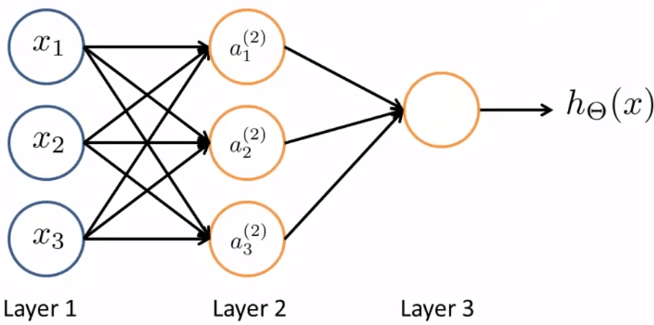
Neuron in AI當有多層 layer 時,我們稱第一層為 input layer 最後一層為 output layer
而中間所有的層統稱為 hidden layers
 3 Layers Neural Networks
3 Layers Neural Networks我們給予上圖 hidden layer 的 nodes 一個名字: Activation units
而這些 activation units 是經由 input 和 Matrix of Weights 作用 output 過來的
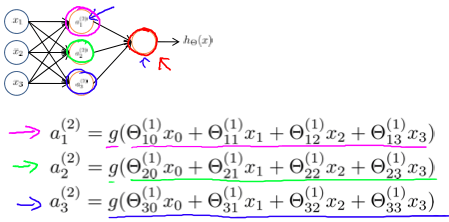
ai(j)Θ(j)=activation of unit i in layer j=matrix of weights controlling function mapping from layer j to layer j+1 舉個例子來說 a1(2),a2(2),a3(2)
就是由 3x4 的 Θ(1) 乘上 4x1 的 input x 向量而來
 Activation Units Operation
Activation Units Operation而 hypothesis hΘ(x) 就是
hΘ(x)=a1(3)=g(Θ(2)a(2))=g(Θ10(2)a0(2)+Θ11(2)a1(2)+Θ12(2)a2(2)+Θ13(2)a3(2)) 我們可以推出 matrix of weight 的 dimension :
- 若 layer j 共有 sj 個 units
- 且 layer j+1 共有 sj+1 個 units
- 那麼 Θ(j) 的 dimension 為 sj+1×(sj+1)
例如 layer 1 有 2 個 nodes 而 layer 2 有 4 個 nodes
那麼 Θ(1) 的 dimension 為 4 x 3
現在我們將每個 g function 內的 Θ 和 x 改為矩陣運算產生的 z
a1(2)=g(Θ10(1)x0+Θ11(1)x1+Θ12(1)x2+Θ13(1)x3)=g(z1(2))a2(2)=g(Θ20(1)x0+Θ21(1)x1+Θ22(1)x2+Θ23(1)x3)=g(z2(2))a3(2)=g(Θ30(1)x0+Θ31(1)x1+Θ32(1)x2+Θ33(1)x3)=g(z3(2)) 也就是說在第 j 個 layer 的第 k 個 node,他的 z 就會是
zk(j)=Θk,0(j−1)x0+Θk,1(j−1)x1+⋯+Θk,n(j−1)xn 現在我們進一步將 input x 向量作為 a(1),所以
z(2)a(2)=Θ(1)a(1)=g(z(2)) 然後 a(2) 必須要補個 a0(2)=1 才能繼續
z(3)a(3)=Θ(2)a(2)=g(z(3))=hΘ(x) 總結來說,z 和 a 的公式如下
其中的 n + 1 為 a0(1)=x0,a0(2),a0(3),⋯
z(j)a(j)=Θ(j−1)a(j−1) where dim(Θ(j−1))=sj×(n+1)=g(z(j)) 我們可以看到其實將最後一個 hidden layer 計算出 output layer 的過程
等同於將最後一個 hidden layer 的每個 activation units 作為 features 執行 logistic regression
而這些 activation units 其實又都是上一層的 nodes 執行 logistic regression 而來
所以這個方法稱作 Forward Propogation
意思是每一層都將計算出更有深度意義 (complex) 的 Hypothesis 至下一層
產出最好的 Hypothesis function
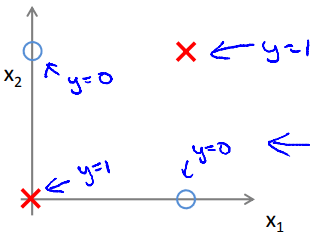
我們將使用 XNOR (NOT XOR) 的例子來解釋為何 neural networks 為何可以成功
 XNOR classification
XNOR classification首先我們先來看 AND, OR 和 NOR 在 neural networks 的實作 :
我們將 activation function 設成以下狀態
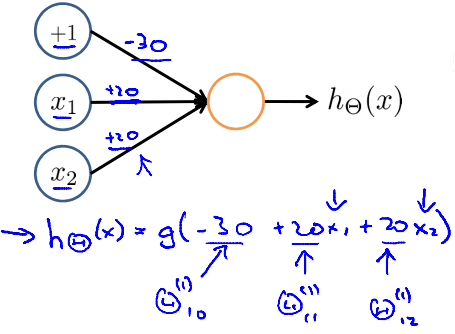 AND neuron
AND neuron我們知道 sigmoid function 在大於 4.6 時差不多為 1
在小於 4.6 時差不多為 0
所以我們帶進去得到
| x1 | x2 | hΘ(x) |
|---|
| 0 | 0 | g(−30)≈0 |
| 0 | 1 | g(−10)≈0 |
| 1 | 0 | g(−10)≈0 |
| 1 | 1 | g(10)≈1 |
所以這個 hΘ(x) 可以說是 AND 的 best hypothesis
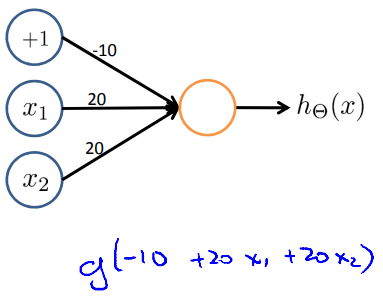 OR neuron
OR neuron| x1 | x2 | hΘ(x) |
|---|
| 0 | 0 | g(−10)≈0 |
| 0 | 1 | g(10)≈1 |
| 1 | 0 | g(10)≈1 |
| 1 | 1 | g(30)≈1 |
這個 Neural network 產生的 hΘ(x) 也可以說是 OR 的 best hypothesis
首先 Negation 的 hypothesis 產生如下
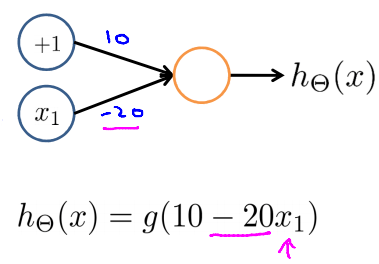 Negation neuron
Negation neuron| x1 | hΘ(x) |
|---|
| 0 | g(10)≈1 |
| 1 | g(−10)≈0 |
而 NOR 其實就是 (NOT x1) AND (NOT x2)
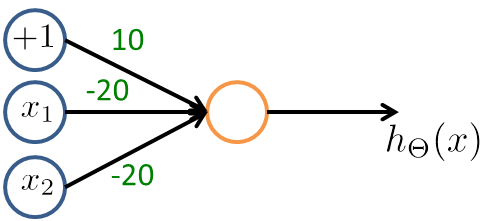 NOR neuron
NOR neuron| x1 | x2 | hΘ(x) |
|---|
| 0 | 0 | g(10)≈1 |
| 0 | 1 | g(−10)≈0 |
| 1 | 0 | g(−10)≈0 |
| 1 | 1 | g(−30)≈0 |
現在我們有了三種 Θ for AND, OR, NOR
AND Θ(1)NOR Θ(1)OR Θ(1)=[−302020]=[10−20−20]=[−102020] 我們將 AND 和 NOR 的 Θ 分別擺到第一層運算
而 OR 則是在最後運算
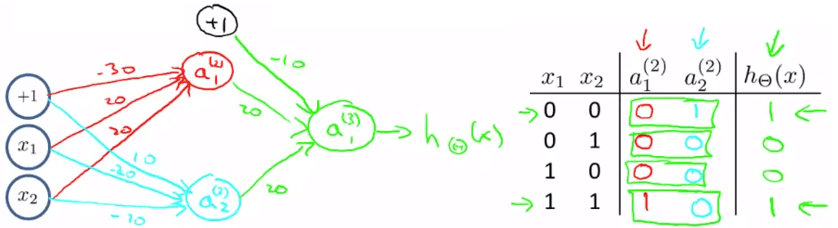 XNOR neuron
XNOR neuronΘ(1)Θ(2)a(2)a(3)=[−301020−2020−20]=[−102020]=g(Θ(1)⋅x)=g(Θ(2)⋅a(2))=hΘ(x) 現在若 Neural networks 要一次處理多種問題
例如圖片辨識需要一次辨識出 Pedestrian, Car, Motorcycle, Truck
當 training sets 為 (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m)) 時
我們會將 y 和 hypothesis 以 vector 方式輸出
y(i)=⎣⎡1000⎦⎤,⎣⎡0100⎦⎤,⎣⎡0010⎦⎤,⎣⎡0001⎦⎤ 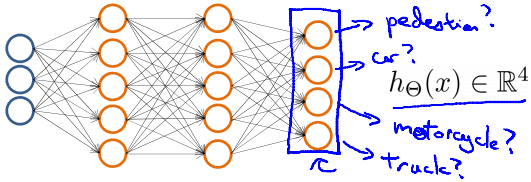 Multi-class neural network
Multi-class neural network若是路人,則 hΘ(x)≈⎣⎡1000⎦⎤
若是車子,則 hΘ(x)≈⎣⎡0100⎦⎤
以此類推 ... 試圖讓 hΘ(x(i))≈y(i)∣Both are R4