本文介紹了 SLAM 的後端技術,主要涵蓋 Kalman Filter、Extended Kalman Filter 和 EKF-SLAM,它們都是用來預測未知環境並更新位置的算法。Kalman Filter 是一種基於線性和高斯分布的演算法,而 Extended Kalman Filter 則是在原本的 Kalman filter 上加入線性近似的概念,最後結合 EKF 用於 SLAM 的技術就是 EKF-SLAM,它將 pose 和 landmark 整合起來定義成狀態,並重新定義 prediction 以及 observation model。
機器人透過 prior 分布 (原本就預測的目的地, xkpre) 和 likelihood 分布 (感應地標後得到的目的地, xkobs)
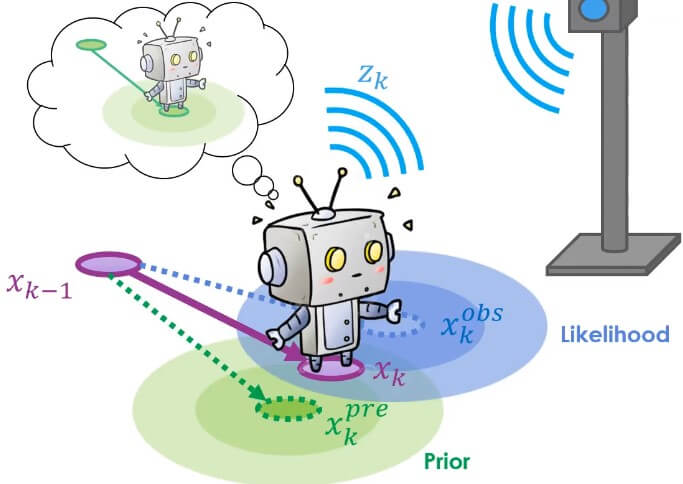 Robot Prior Likelihood
Robot Prior Likelihood結合兩個分布就能得到 posterior 分布 (最終決定移動的點, xkest)
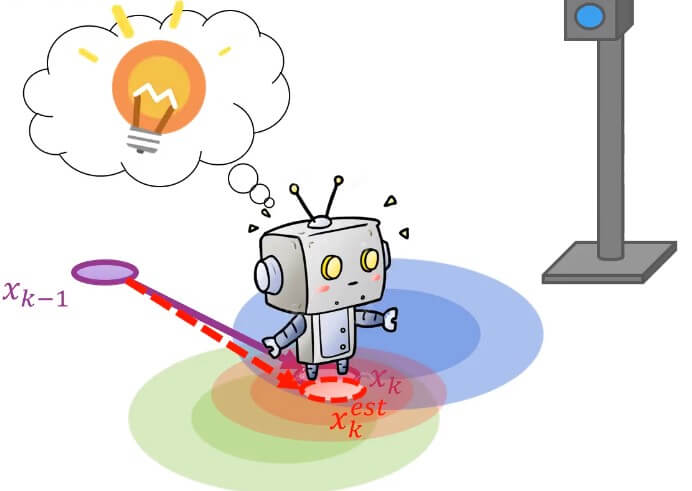 Robot Posterior
Robot Posterior以下是 kalman filter 對狀態的建模
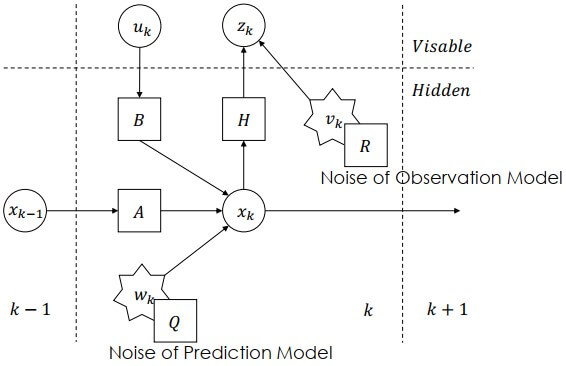 Kalman Filter
Kalman Filter- x-axis: 時間方向
- y-axis: 可觀察、不可觀察
- Noise 的分布 (Q, R) 在假設中皆為高斯分布 (Gaussian distribution)
- Goal: 用可觀察的東西,對不可觀察的東西做出預測
假設所有變換都是線性的,可以得到以下公式:
xk=Axk−1+Buk+wkzk=Hxk+vk 共有四個參數: A,B,Q,R
- 預測下一個狀態
xkpre=Axk−1est+Buk - 計算預測的 covariance
Pkpre=APk−1estAT+Q - 計算 Kalman-gain
Kk=PkpreHT(HPkpreHT+R)−1 - 預測狀態的 mean
xkest=xkpre+Kk(zk−Hxkpre) - 預測狀態的 covariance
Pkest=(I−KkH)Pkpre Kalman filter 線性以及高斯分布的假設讓所有運算都變得簡單
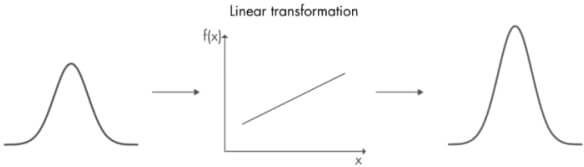 Kalman Filter Distribution
Kalman Filter Distribution但在現實中的狀況大多不是這麼簡單
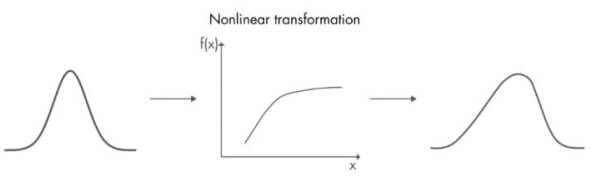 Kalman Filter Distribution in Reality
Kalman Filter Distribution in Reality於是在 Kalman filter 上加入"線性近似"的概念,就得到了 extended Kalman filter,也就是在預測狀態的 mean 時,改用 1st order Taylor expansion 來求
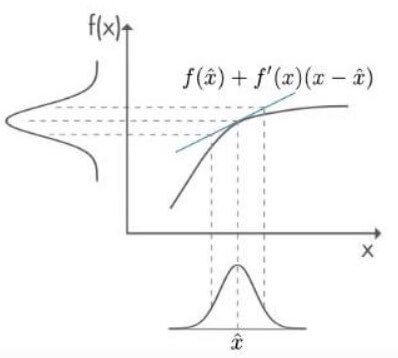 Extended Kalman Filter Taylor
Extended Kalman Filter Taylor可以看到藍色線就是求得的近似線性值,我們可以得到新的公式:
- Prediction Model \& Observation Model
xk=f(xk−1,uk)+wkzk=h(xk)+vk Fk=∂x∂f(x^k−1,uk),Hk=∂x∂h(x^k) xk=f(x^k−1,uk)+Fk(xk−1−x^k−1)+wkzk=h(x^k)+Hk(xk−x^k)+vk 在原本的 Kalman filter 時,計算中的 A, H 都是固定的,而在 EKF 中,每個時間點都須根據前一刻的估計值,重新用第一階的 taylor expansion 求得線性近似:
xkpre=f(xk−1est,uk)Pkpre=FkPk−1preFkT+QKk=PkpreHT(HPkpreHT+R)−1xkest=xkpre+Kk(zk−Hxkpre)Pkest=(I−KkH)Pkpre 為了將 EKF 應用到 SLAM 問題中,首先要將 pose, landmark 定義成狀態 (state)
sk=⎝⎛robot’s posex,y,θ,landmark 1m1,x,m1,y,landmark 2m2,x,m2,y,…,landmark nmn,x,mn,y⎠⎞T 而狀態的分布如下,其中 covariance 可以拆成四個部分 (pose 本身關聯、pose 和 map 關聯、map 本身關聯)
⎣⎡xyθm1,xm1,y⋮mn,xmn,y⎦⎤→μ=[xm],Σ=[ΣxxΣmxΣxmΣmm] ⎣⎡x′y′θ′⎦⎤=⎣⎡xyθ⎦⎤+⎣⎡−ωvsin(θ)+ωvsin(θ+ωtΔt)ωvcos(θ)−ωvcos(θ+ωtΔt)ωΔt⎦⎤ - Linearized the velocity motion model (對 prediction model 微分)
Ftx=∂(x,y,θ)T∂f⎣⎡x′y′θ′⎦⎤=⎣⎡100010−ωtvtcos(θ)+ωtvtcos(θ+ωtΔt)−ωtvtsin(θ)+ωtvtsin(θ+ωtΔt)1⎦⎤ 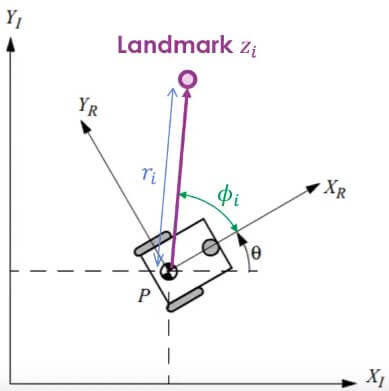 EKF-SLAM observation model
EKF-SLAM observation modelzi=[qatan2(δx,δy)−θ],δ=[mi,x−xmi,y−y],q=δTδ - Linearized the observation model (對 observation model 微分)
Hi=∂(x,y,θ,mi,x,mi,y)∂zi=q1[−qδxδy−qδy−δx0−qqδx−δyqδyδx] - 矩陣大小為 2 * 5
- 2 為某個地標的 x, y 座標
- 5 為自走車 pose 的 3 個變數 + 地標的 2 個座標 (x, y)
- 如果今天觀察 l 個地標
我們可以建構關聯性的轉換矩陣,把上面兩種的局部結果,轉換到全局的整個狀態情況下
- Prediction model (3*n, n 為狀態數量)
Ft=⎣⎡100010001000⋯⋯⋯000⎦⎤T×Ftx - Observation model (5*n, 左上角 3 個與 pose 有關, 其餘每 2 個為 landmark)
Ht=⎣⎡10000010000010000000⋯⋯⋯⋯⋯00000000100000100000⋯⋯⋯⋯⋯00000⎦⎤×Hti 有了全局的 Ft,Ht 就可以帶進 EKF 中開始計算
xkpre=f(xk−1est,uk)Pkpre=FkPk−1preFkT+QKk=PkpreHT(HPkpreHT+R)−1xkest=xkpre+Kk(zk−Hxkpre)Pkest=(I−KkH)Pkpre