本文接續 SLAM Back-end I,主要介紹了 Filter-based Back-end、Grid-based Back-end 以及 Graph-based Back-end。 第一部分主要介紹 Particle Filter、Sampling 以及 Sequential Importance Sampling (SIS) 和 Sequential Importance Resampling (SIR),以及由此衍生出的 Fast-SLAM 方法。 第二部分主要介紹 Occupancy Grid Map,以及如何利用 Laser Beam Model 更新地圖狀態以及 Particle weighting,最後介紹了 Grid map 套用 Fast-SLAM 的完整過程。 第三部分主要介紹 Graph Optimization 的方法,以及用 ICP algorithm 找出兩個 scan 之間的對應關係。接著介紹 Map & Pose 以及 Grid-based SLAM。
Filter-based backend 是及時使用前一刻的資訊來修正目前的誤差,但會慢慢累積誤差。
Particle Filter
前一章節講到的 EKF-SLAM 將機器人的 pose, landmarks 的機率分布都預設是 Gaussian,產生了一些缺點:
- 無法很好表達機器人的 pose
- 計算 pose 和 landmarks 的 covariance matrix 成本很大 (O(K2))
Particle filter 會應用 importance sampling 來計算大約的隨機分布 (arbitrary distribution),而且複雜度變為 O(MlogK)
- 在 statistical modeling and inference 有很多困難問題用 closed-form of P(X) 無法計算
- 所以會使用 tatistical sampling and simulation 來從目標分布中取得 fair samples
以下介紹四個與 sampling 有關的方法,分別是 basic sampling, importance sampling, sequential importance sampling (SIS) 和 sequential importance resampling (SIR)
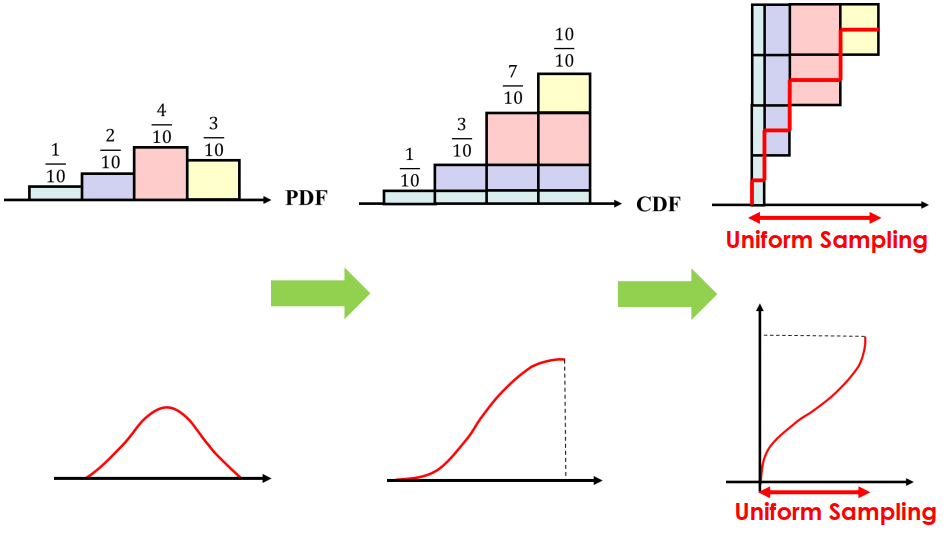 Basic Sampling
Basic Sampling從離散 sampling 推得連續 sampling,將連續 sample 倒過來看就像是在 0-1 之間取 uniform sampling
Importance sampling 利用 discrete multinomial 來求近似的 arbitrary distribution,越多的 sampling particles 可以得到越準的近似值
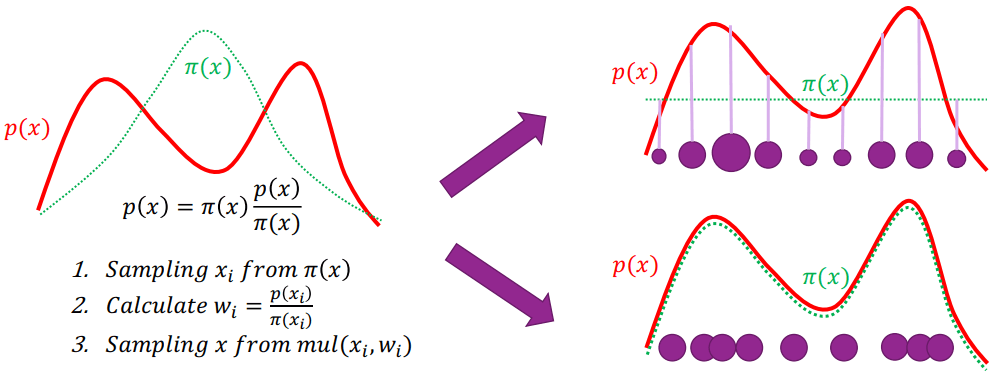 Importance Sampling
Importance Sampling- 用簡單的分布 (π(x)) 來近似目標分布 (p(x))
- 可以看到第二項 π(xi)p(xi) 是一種權重
- 若 p(xi) 遠大於 π(xi) 代表和目標還差很多,可以調整
- 差距越大右上圖中的圓點就越大,則下一次又被採樣調整的機率就越大
- 會讓 π(xi) 近似 p(xi)
- 若 π(xi) 接近 p(xi) 那麼 weight 就會變成右下圖 (圓點大小一樣)
首先先考慮機器人定位的問題,我們使用一些 particles 來表示近似的 pose distribution
- 在 importance sampling,每個 particle 都有自己的 pose 和 weighting
weighting =target distributionsource distribution=wt(i)=π(x1:t(i)∣z1:t,u1:t−1)p(x1:t(i)∣z1:t,u1:t−1) 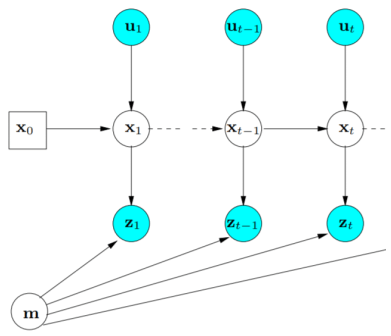 Sequential Importance Sampling
Sequential Importance Sampling- 根據上圖,可以將 weighting 拆成 t 和 1:t-1 的機率相乘 (skip formula)
- 我們可以再套入 Bayes theorem (skip formula)
- 最後可以得到一個公式來 update weighting
wt(i)=wt−1(i)p(xt(i)∣xt−1(i),ut−1)ηp(zt∣mt−1,xt(i))p(xt(i)∣xt−1(i),ut−1)∝wt−1(i)⋅p(zt∣mt−1,xt(i)) 在實作中會先隨機灑下一些 particles (same weighting),並在每一步 (sequential) 對未知的預測 p 進行 sampling,然後更新 weighting
SIS particle filter 中的 particles 會隨著步數增加 weighting 會慢慢退化、不見,或可能變得更大,為了解決該問題,我們新增了 resampling 的步驟
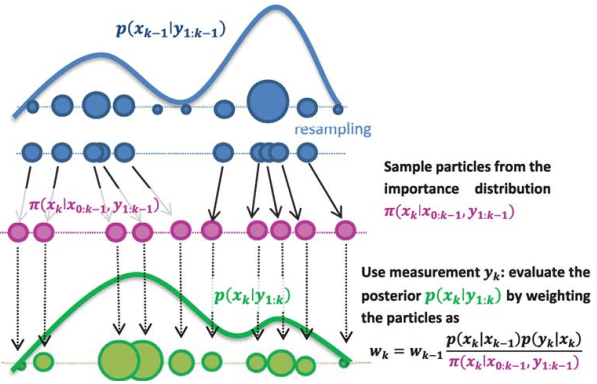 Sequential Importance Resampling
Sequential Importance Resampling- 對最上面已經快要走歪的分布進行 resampling
- 原本較大 weighting 的點變成同樣大小的點,但數量變多
- 就可以重新進行 SIS
Particle filter 只處理到定位的問題,整個 SLAM 問題有定位 (localization) 和建圖 (mapping),需要用 Fast-SLAM 來解決。
Fast-SLAM 將原本要一起進行的定位和建圖拆成各自的工作 (disentangle),這方法叫做 Rao-Blackwellization,能降低 SLAM 問題的計算複雜度
p(x1:t,mt∣z1:t,u1:t)=p(x1:t∣z1:t,u1:t)p(mt∣x1:t,z1:t)
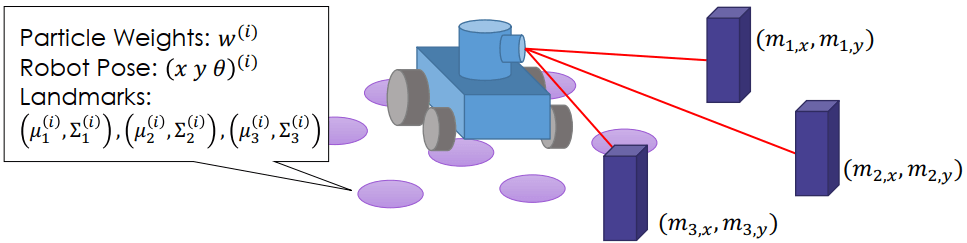 Fast-SLAM
Fast-SLAM- 每個 particles 原本有存機器人的 pose 和 weighting
- 現在多存了每個 landmarks 的機率分布資訊
- 由 EKF 獨立計算每個 landmarks 的 posterior 估計
- 每個 landmark 之間都是互相獨立,所以可以用連乘得到所有 landmarks 的聯合機率分布
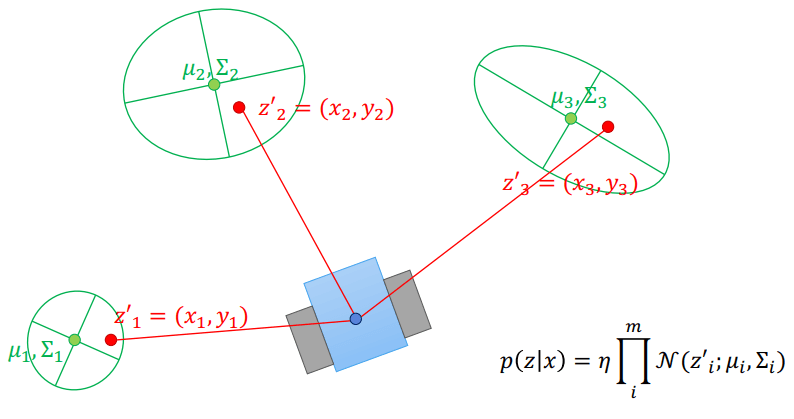 Fast-SLAM
Fast-SLAM整個 Fast-SLAM 可以整理成如下,可以想成是 SIR 的延伸:
- 用 motion model 來採集多個 particles (用來預測下一個 pose xt(i))
xt(i)∼p(xt(i)∣xt−1(i),ut−1)
- 用 EKF 來更新單一 landmark 的地圖建構 (distribution of each landmark (μj,t(i),Σj,t(i)))
Q=HΣj,t−1(i)HT+R,Kt=Σj,t−1(i)HTQ−1μj,t(i)=μj,t−1(i)+Kk(zk−h(μj,t−1(i),xt(i)))Σj,t(i)=(I−KtH)Σj,t−1(i) - 更新 importance sampling 中的 particle weighting
w(i)∼∣2πQ∣−21exp{−21(zk−h(μj,t−1(i),xt(i)))TQ−1(zk−h(μj,t−1(i),xt(i)))} - Resampling
- 複製 particle (M) 和 landmark (K) = O(M×K)
- 因為可能會重複 sample 到同一個 pose 或 landmark
下面介紹兩個 Fast-SLAM 的改進方法,分別是將 resample 的次數降低,以及改變 particles 的資料結構。
若 particle 沒有退化,那可以不用進行 resampling
- 用 Neff 知道 particle weighting 分布均不均勻
- Neff 代表 weighting 的 variance inverse
- 越平均則 Neff 會越大,接近粒子數量 N
- 越不平均則 Neff 會越小
- 當 Neff 小於一個 threshold (e.g., particles 數量的一半) 再進行 resample
Neff=∑i(wt(i))21<2N Particles 資料結構
因為在 resample 進行複製很花成本,所以利用 balanced binary tree 來表示 particles,就可以用改指標的方式省略複製過程
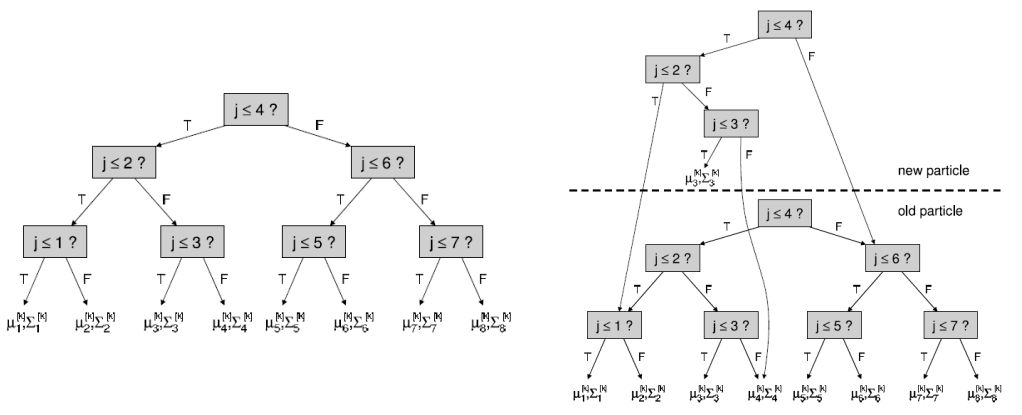 Fast-SLAM
Fast-SLAM實際情況下要得知 landmark 不是容易的事,所以有另一種表達方式稱為 Occupancy Grid Map。 這種表達方式可以用來 model 任何類型的環境,不需要任何事先定義好的 landmarks。
 Occupancy Grid Representation
Occupancy Grid Representation使用 Grid Map 進行的 Fast-SLAM 只有兩個地方不同,分別是第二和第三步骤
- Predict the next pose xt(i) by motion model.
- Update the occupancy grid map of each particle.
- Update the importance weight of particles.
- Resampling.
地圖上的點會用有無佔領表示 (rate of occupied/free)
Odd(s)=p(s=0)p(s=1)(s=0=free) 利用 Bayes theorem 可以得到後驗機率等於 odd 乘上有無佔據的觀察結果
Odd(s∣z)=p(z∣s=0)p(z∣s=1)Odd(s) 可以用 log 來減化算式得到:
logOdd(s∣z)=logp(z∣s=0)p(z∣s=1)+logOdd(s) 實際演算法當中,會定義兩個參數用來表示佔據和沒有佔據:
locc=p(z=0∣s=0)p(z=0∣s=1)lfree=p(z=1∣s=0)p(z=1∣s=1) 而一開始每個點的佔據 (locc) 和沒有佔據 (lfree) 都是 0.5,所以 grid 狀態就是:
logOdd(sinit)=logp(sinit=0)p(sinit=1)=log0.50.5=0 當 laser 往障礙物發射後,就可以更新 lfree 到所有沒被佔領的地方,而最後 laser 碰到的點就更新 locc 上去
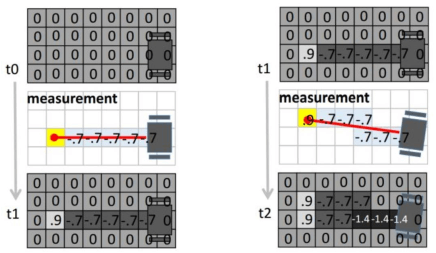 Occupancy Grid Map Algorithm
Occupancy Grid Map AlgorithmUpdate Particle weighting
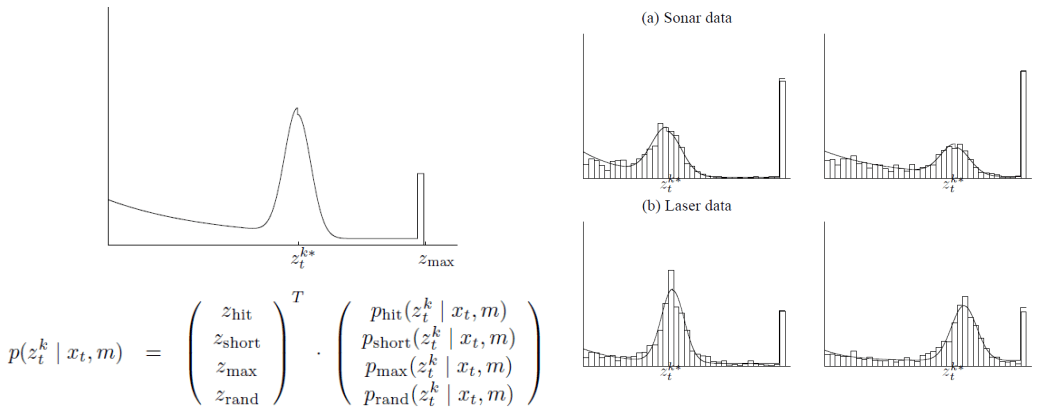
因為是用 laser 來量測周圍,所以對於障礙物 ztk 可能會有幾種量測 model,加起來可以組出 laser beam model
 Laser Beam Model
Laser Beam Model(a). laser 有打到障礙物,在障礙物上產生 Gaussian 分布
(b). laser 打到經過的移動物 (人狗貓),會產生 exponential 分布
(c). laser 沒有打到障礙物,沒有把光線反射回來,會回傳 zmax 的值
(d). Sensor 接收到錯誤的回傳光線 (其他光反射折射),產生 uniform 分布
將以上四種可能組合成 mixture distribution 就可以得到 laser beam model
 Laser Beam Model Mixture
Laser Beam Model Mixture要在考量這四種分布出現的機率,所以要將分布再乘上這些機率 (zhit,zshort,zmax,zrand)
給定 particle (x, y) 和 laser beam model (ztk),就可以在地圖上找到 laser 的終點位子 (紅色點)
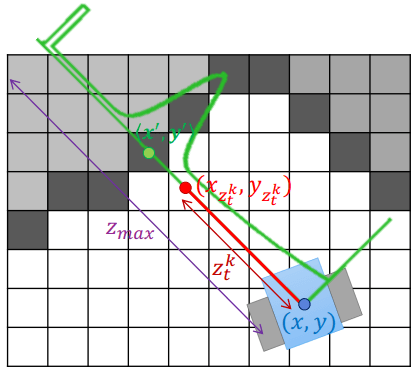 Laser Beam Model 2
Laser Beam Model 2- 接著就可以找到 laser 路徑上最近的 occupied grid (x', y')
- 我們可以將這條線畫成一個綠色分布
- 知道紅色點的在綠色分布上的機率,就可以得到這條 laser 上的 likelihood 分布
 Laser Beam Model Algorithm
Laser Beam Model Algorithm演算法如上,可以得到該時間點量測的 likelihood 分布 :
- 第 4 行驗證如果 laser 沒有失敗才繼續
- 第 5, 6 行考慮 sensor 不在車子中心點進行調整並算出紅色點
- 第 8 行每條 laser 獨立,所以可以聯乘
- 對每個 particle 去 sample 不一樣的預測 pose
xt(i)∼p(xt(i)∣xt−1(i),ut−1) - 進行 ray trace 來更新地圖 grid map 每個 grid 的狀態 (likelihood)
logOdd(s∣z)=logp(z∣s=0)p(z∣s=1)+logOdd(s) - 使用 laser beam model 計算機率聯乘得到觀測的 likelihood,並將所有 particles 的 likelihood 做 normalization 得到更新的 weighting
wt(i)=ηi∏(zhit⋅prob(dist,σhit)+zmaxZrandom) - Resampling
以上就是將 Grid map 套用 Fast-SLAM 的完整過程
Filter-based 講到要找到 pose (x) 和 landmark (m) 可以使用 MAP 或 MLE 做法,但都會出現誤差
(x,m)MAP∗=argmaxP(x,m∣z,u)=argmaxP(z,u∣x,m)P(x,m)(x,m)MLE∗=argmaxP(z,u∣x,m)eu,k=xk−f(xk−1,uk)ez,k,j=zk,j−h(mj,xk) 為了要最小化誤差,可以將式子寫成以下 optimization 的樣式:
minF(x,m)=∑keu,kTRK−1eu,k+∑k∑jez,k,jTQK,j−1ez,k,j
例如下面 graph 中機器人的偵測存在著誤差,我們就可以將誤差寫做 error function,而我們的目標就是最小化由 error functions 累積形成的 F(x,m)
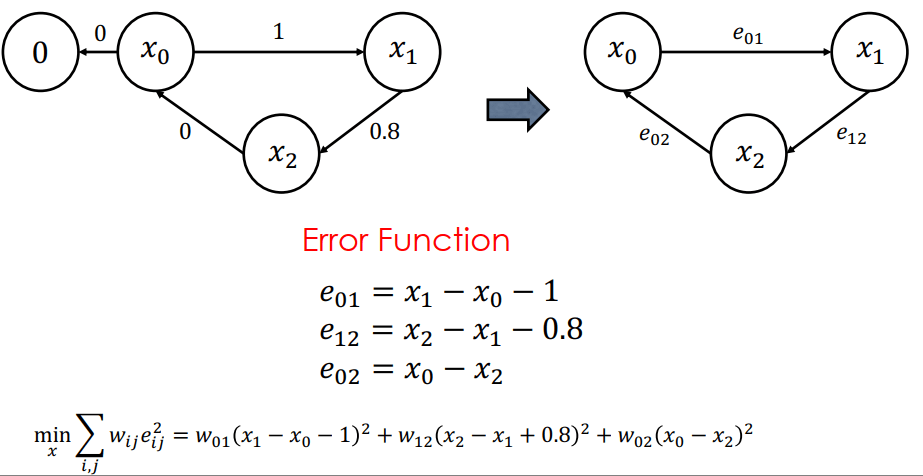 Graph Optimization
Graph Optimization有兩個現成工具可以解決 optimization:
要解上面 F(x,m) 這種 non-linear optimization 問題,有幾種做法:
 Basic Optimization
Basic Optimization當問題中每個函式都是簡單的,就可以直接用微分等於零求解 (dxdF),若微分變得非常複雜就只好求 local minimum
 Basic Optimization
Basic Optimization因為問題通常都是 non-linear 的,所以會呈現下圖這種例子
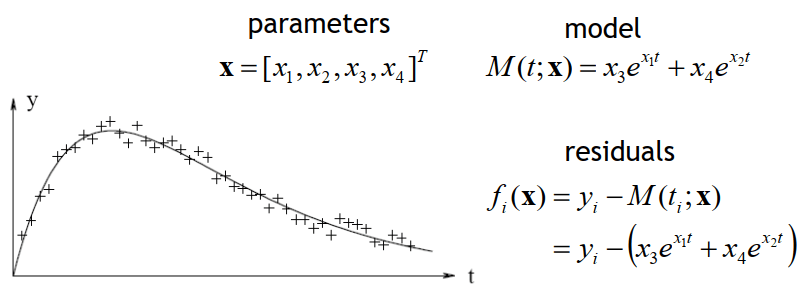 Basic Optimization
Basic Optimization我們可以將問題寫成 x 的 Taylor expansion:
F(x+h)≈F(x)+J(x)Th+21hTH(x)h
後面的 J(x) 和 H(x) 分別代表 F(\mathbf{x}) 的一階和二階導數,求導數是為了變為曲面以便尋找 local minima
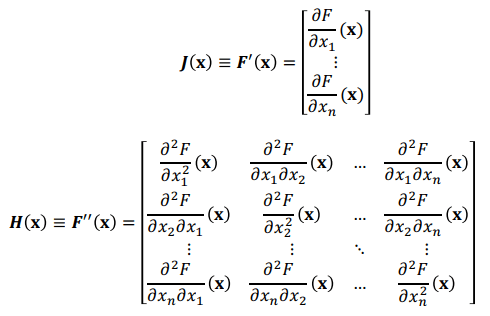 Taylor Expansion Derivative
Taylor Expansion Derivative例如以下是一個典型 quadratic functions,我們可以透過其中的 A 矩陣來判斷曲面的形狀
F(x)=21xTAx−bTx+c,A=[3226]  Quadratic Functions Shape
Quadratic Functions Shape::: note
要解最佳化的方法有以下幾種:
:::
在 2D 平面我們可以觀察兩個 pose 的關係
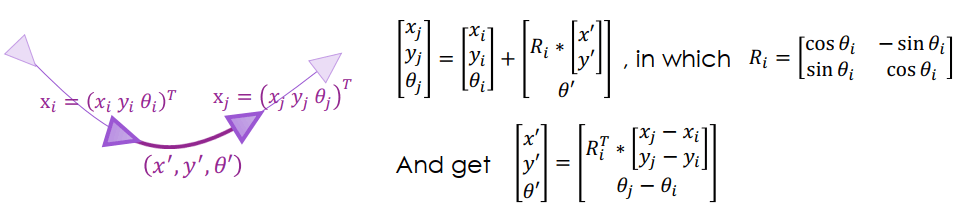 Graph Optimization for 2D
Graph Optimization for 2D我們可以將 error 寫成觀測和預測的差
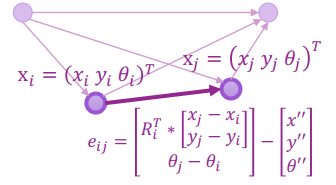 Graph Optimization for 2D Error
Graph Optimization for 2D Error目標就是得到 optimal poses F=∑i,jeijTΩeij,可以用一階 taylor 求近似解
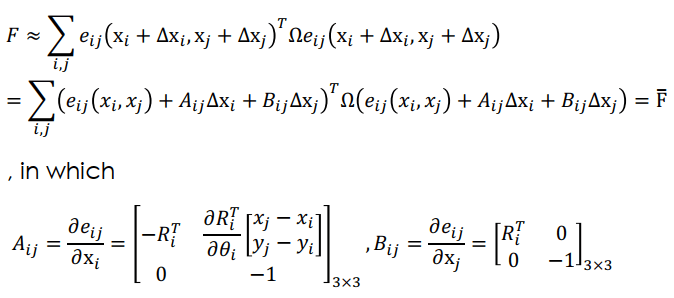 Graph Optimization for 2D Taylor
Graph Optimization for 2D Taylor可以用 Gauss-Newton 來解 approximation function F 並轉成矩陣形式
 Graph Optimization for 2D Gauss-Newton Matrix
Graph Optimization for 2D Gauss-Newton Matrix現實中可能沒辦法取量測值 (x′,y′,θ′),做法是使用 scan-to-scan registration
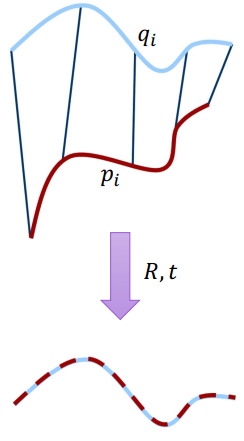 Scan-to-Scan Registration
Scan-to-Scan RegistrationScan-to-scan 方法是計算時間點之間改變的 transformation,用每個時間點的所有點集合,和下個時間點的點集合,來求出轉換關係,也就是求出以下的最佳化公式:
J=21i=1∑n∥qi−Rpi−t∥2 我們可以假設兩組點集合的 mean (μp,μq),改寫上面式子
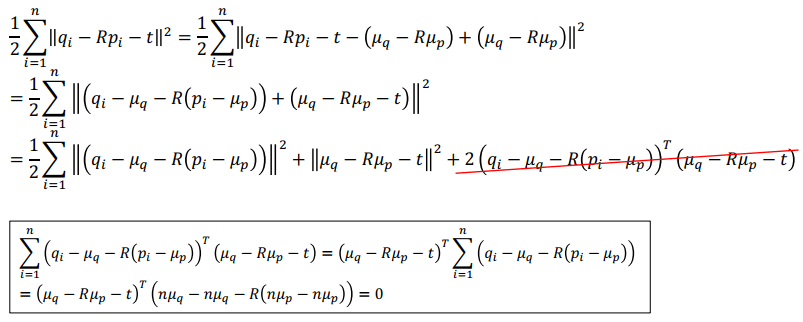 Scan-to-Scan Registration
Scan-to-Scan Registration計算時找出對應 μp,μq 的相對位置 (pi′,qi′) 之後,可以將最佳化拆成兩個階段,先求 rotation (R) 再求 translation (t)
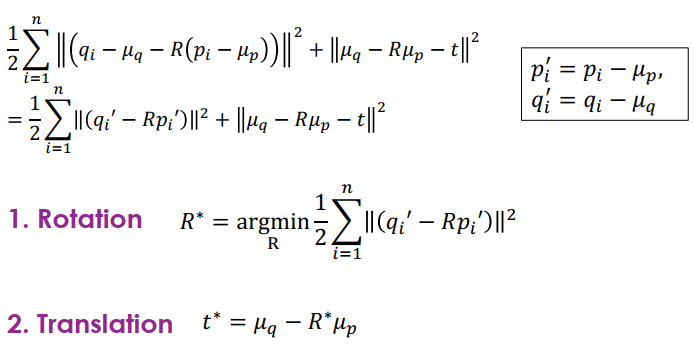 Scan-to-Scan Registration
Scan-to-Scan Registration因為 q, p 分別對應兩個時間的 scan 所以稱為 scan2scan
因為可能不知道 p 和 q 之間絕對的對應關係,所以要用 ICP algorithm,ICP 也像一種最佳化,不斷初始化,並觀察是否最好,不是則更新。
 Scan-to-Scan Registration ICP
Scan-to-Scan Registration ICP上面只考慮了 pose 的部分,現在多考慮 landmarks,變成 bipartite 圖
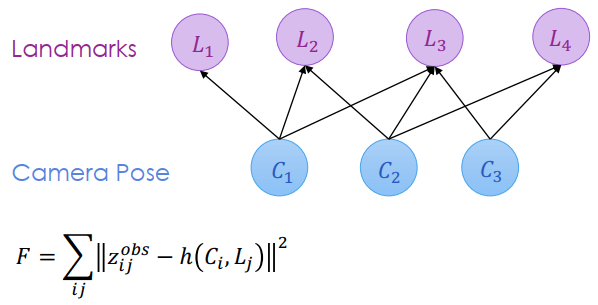 Graph Optimization for Map and Pose
Graph Optimization for Map and Pose我們運用 bundle adjustment 方法,讓 pose 之間、 landmark 之間都沒有關係,得到觀測模型 zij=h(Ci,Lj) 就可以進行最佳化。
若是 landmarks 改用 grid map 形式的話,有兩種做法分別是 Karto-SLAM (開源) 和 Cartographer (Google)
 Graph Optimization for Grid-based SLAM
Graph Optimization for Grid-based SLAM假設 robot pose 為 ξ=(px,py,ψ) 而 landmarks 為激光打到的 (sx,sy) (要轉成 world coordinate)。我們要最大化 grid 是 1 (被佔) 的機率,等於最小化 grid 是 0 (沒有被佔) 的機率
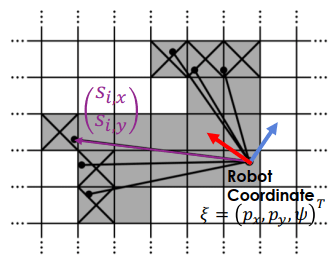 Scan-to-Map Matching
Scan-to-Map Matching