Bioinformatics
Genomics 是指研究生物染色體的結構和功能。對於生物染色體的結構來說,人體大概有 3 億個核苷酸 (A、C、G、T) 組成基因組,而基因組又被分成 23 個染色體(22 個普遍的 + XX 或 XY),而每個染色體又有着 centromere 和 telomere。對於基因組的功能來說,它包含了所有身體會使用到的東西,例如呼吸代謝、大腦等等。
Bioinformatics 是 Genomic Data Science 的另一種名稱,它是結合了 biology,statistics 以及 computer science 的一種技術。Bioinformatics 主要是用來收集任何主題的細胞樣本,並對這些樣本執行 sequencing 以產生大量的資料,這些資料會被稱為 reads,接著將這些 reads 與 reference genome(例如標準歐洲男性基因組)對齊,並開始分析差異,最後儲存到公開的 database(例如 NCBI),以便研究者進一步分析。
Why genomics ?
Central dogma 不是標準原則
- Central dogma 不是準則,有非常多的變異點
- DNA 生成的 Protein 可以回來和 DNA 結合
- 一些 modifiers (methylation) 可以改變 DNA
- 所以 information 不只順著影響,也會逆向影響
Sequencing
- Sequencing 是 genomics 的核心
- 了解 gene 的所有影響
- 因為 sequencing 的進步,可以測出單個 tumor 的 genome
- 但目前無法完整分析
可以到 NCBI (National Center for Biotechnology Information) 下載這些已經定序好的 gene data
What is genomics ?
如果是指 structure:
- 人類身體大約有 3 billion 個 nucleotides (As, Cs, Gs, Ts) 組成 genome
- 所有 genome 都被分成 23 個 chromosomes (22 + XX or XY)
- Chromosome 又有 centromere 和 telomere
如果是指 function:
- Genome 能做什麼 ?
- Encode 所有身體會用到的東西
- Respiration metabolism
- Building brain
如果是指 evolution:
- 一代一代傳下來的 genome 是幾乎沒有什麼變的
- 但可以和其他生物比較
Difference between Biology-Genetics and Genomics
| Biology-Genetics | Genomics | |
|---|---|---|
| Scope | targeted one or few genes | all genes in a genome |
| Technology | targeted, low-throughput experiments | global, high-throughput experiments |
| Hard part | 設計良好實驗、不斷重複實驗 | 大數據、大量計算、不確定性 |
What Is Genomic Data Science?
- Genomic Data Science = Bioinformatics
- 包含 biology, statistics, computer science
Bioinformatics 在做什麼 ?
- 收集任意 subject (e.g. human) 的細胞樣本
- 對樣本執行 sequencing
- 產生大量的 data
- 每個 sequences 都是小片段,又稱為 reads
- 將這些 reads 和 reference genome (e.g. average european male) 對齊
- 開始分析差異
- 儲存這些資料、分析結果到公開的 database (e.g. NCBI)
- 對這些公開資料可以進一步分析
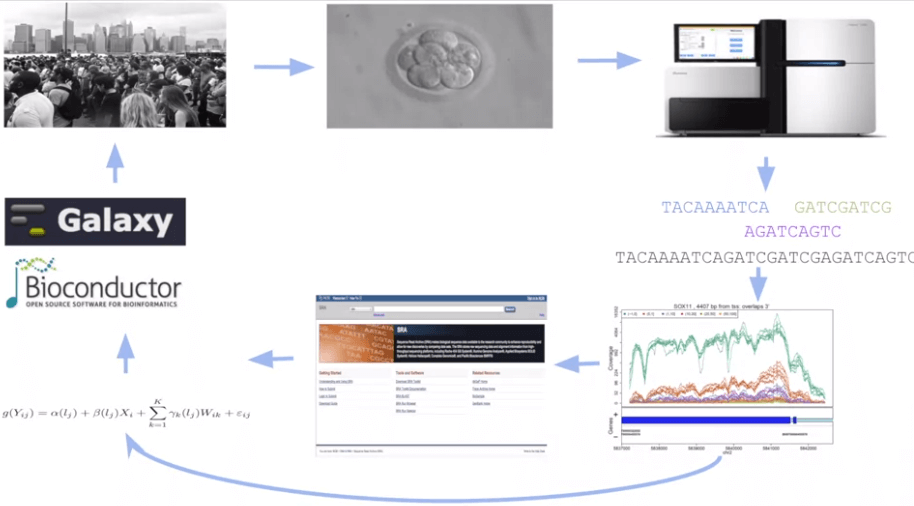
上圖順時針共有 8 個步驟,對應於一些重要領域
- Experimental design (1, 2, 3)
- 設計出你想研究的東西,產生 data
- Alignment & Assembly (3, 4)
- 將 data 與 reference genome 對齊,找出差異,集中結果
- Preprocessing & Normalization (4, 5)
- 避免巨量 data 產生 bias 所以要正規化
- Statistics & Machine learning (5, 7)
- 用一些技巧來得出結論
- Software development (8)
- 利用現成軟體來加速進行
- Population genomics (5, 7, 8, 1)
- 不一定只有找出 cancer 原因,也能找出同一群人的特徵 (e.g. 容易得到疾病)
- Integrative genomics (6, 7, 8, 1)
- 把所有結果整合
The human genome project
- 1989 開始由 NIH + DOE (US) 主導
- 一開始目標,在 2005 前 sequence 3 billion basepairs ($1 per base)
- Early 1990s
- busy creating maps
- analyze small or large pieces of DNA
- 1995
- TIGR (Craig Venter)
- 在 haemophilus influenzae (嗜血桿菌) 序列出完整基因
- 1.8 million bases
- 1742 genes
- 1998
- new sequencing machine
- Celera Genomics company
- June 2000
- completion of the human genome
- "Draft"
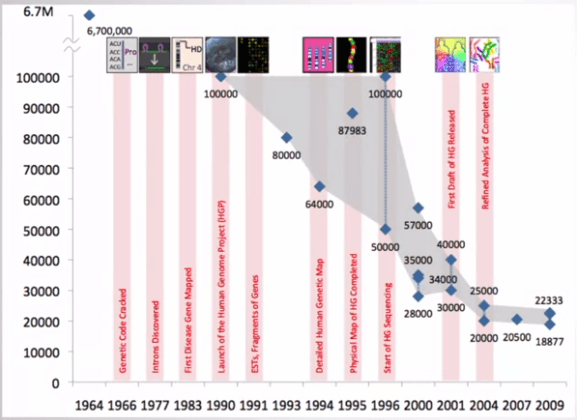
How many genes do we have ?
在 3 billion 的 bases 中,有多少 encoded genes ?
- 1964
- 6.7 million genes?
- Feb 2001 (Nature 409)
- 30000 - 40000 genes
- Feb 2001 (Science 291)
- 26588 genes + 12000 likely genes
- Today
- 99.9% genome have been sequenced
- 22000 - 23000 genes
Project result
- sequence 3 billion basepairs - succeed!
- $1 per base - $1 per 700 bases!
- 700 bases are one read
- by 2005 - done in 2001!
- Cost today - $1 per 3 million bases!
- 4000-fold cheaper
Measurement Technology
Polymerase Chain Reaction (PCR)
- PCR 是製作 DNA copy 的一個重大技術
- 用 DNA polymerase 幫助複製
- 因為每做一回合,就拿到雙倍的 DNA copy,是一個 chain reaction

- 製作材料
- DNA
- Primers (告訴 DNA polymerase 哪裡開始複製)
- DNA polymerase
- A's, C's, G's, T's
- Recipe
- 加熱到 94 度 C
- 退火 (冷卻) 到 54 度 C
- 回溫到 72 度 C
- 回到第一步 (約 30 次 cycle)
首先 2 個 primers 附到 DNA 的兩側開頭 (綠色和藍色)
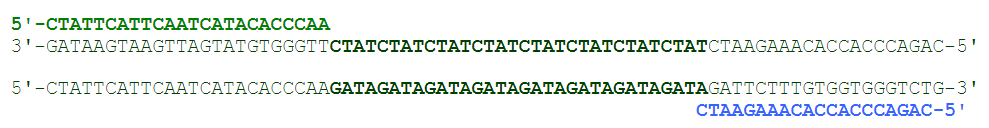
慢慢加熱,使得 DNA double-strand 和 primers 都慢慢分開
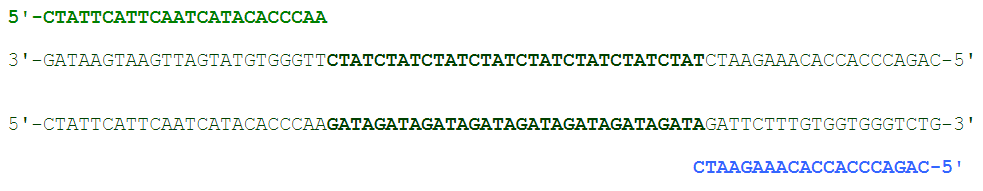
再來慢慢冷卻,不讓 DNA 回復,但讓 primers 回復
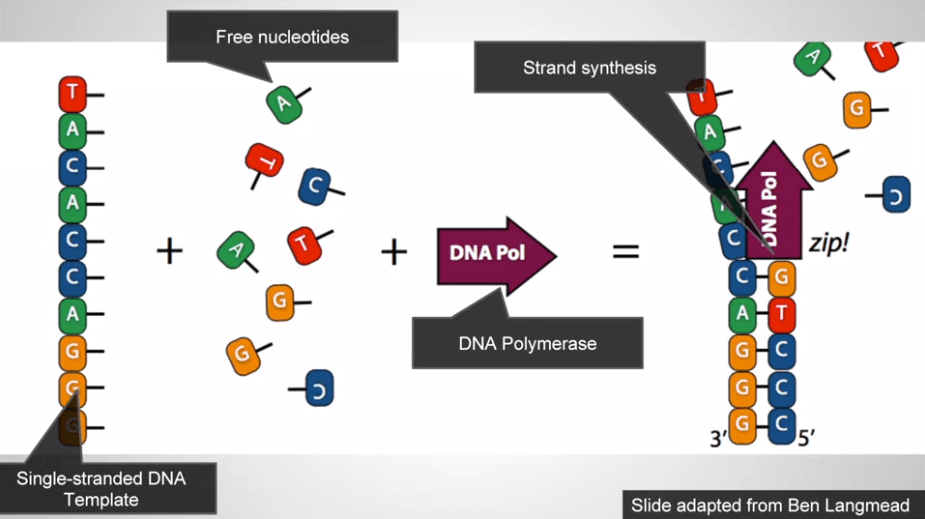
讓 DNA polymerase 還有一堆 As, Cs, Gs, Ts 加入,開始複製 DNA (溫度些微加熱)

我們得到了一倍的 DNA copy,下一輪也是如此

通常持續 30 次迴圈,所以共可產生 2^30 個 DNA copy (約十億個 DNA copy)
Next Generation Sequencing (NGS)
- 現在所用的 data 多為 2007 之後 NGS 技術所產生的 sequencing data

Recall 一下 DNA 是怎麼複製的:
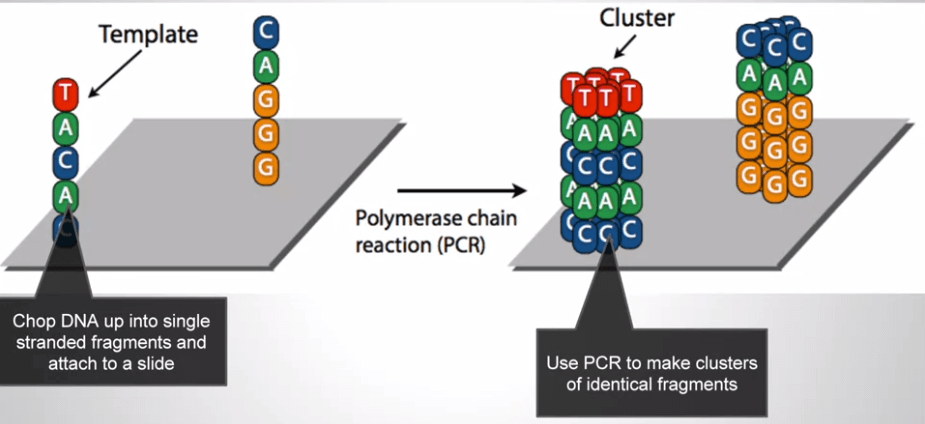
NGS 將大量 template DNA 放在 slide 上面,下圖只用兩個舉例
對大量 template DNA 進行 PCR,產生 copy
利用這個原理,對將被用來複製的 nucleotides 塗上顏色
在他們被複製時按下快門,就可以看到顏色得到對應的原 bases
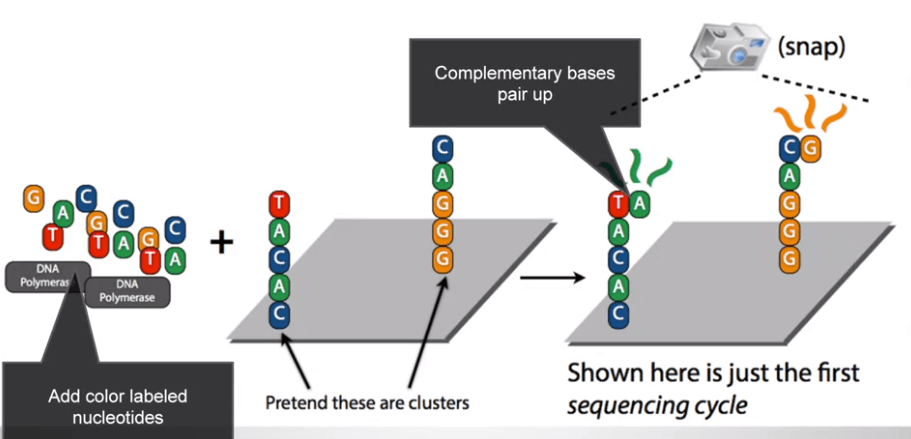
重複在每個 base 被加入時拍照,就可以得到原本的 sequence
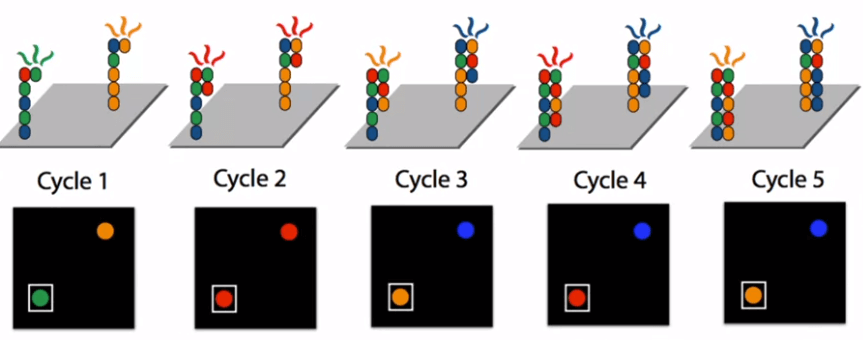
但在越後面的 cycles 會出現越多的錯誤
例如某一些 template 的速度較其他 template 快,某些較慢。所以無法同時一次讀取上千個 base
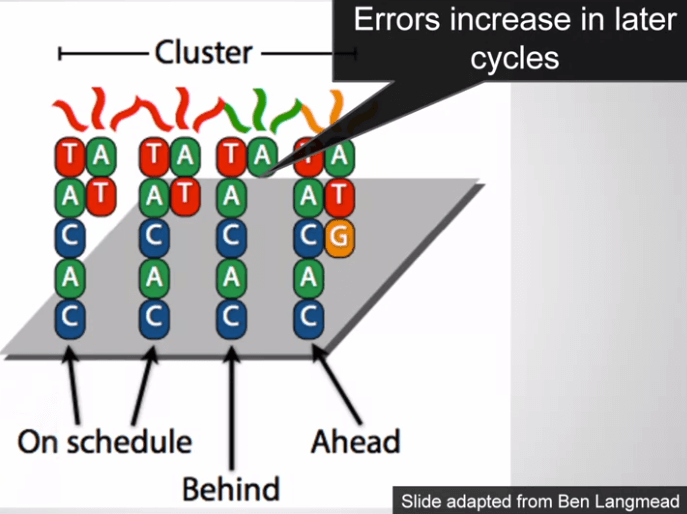
最終結果如下,有的跟在 ACGT 的是 quality value (正確率)
Quality value 由些 base calling 軟體來評估

Application of Sequencing
由於 NGS 可以非常快速定序,且又非常便宜,所以產生了一些相關的應用
- Basic idea
- 轉換一些東西變成 DNA (例如 RNA)
- 對 DNA 進行 NGS
Exome sequencing
- 人類大約有 1.5% genes (30 to 60 million bases) 是 exons
- Exons (Exome) 是 genome 中負責 protein-coding 的 genes
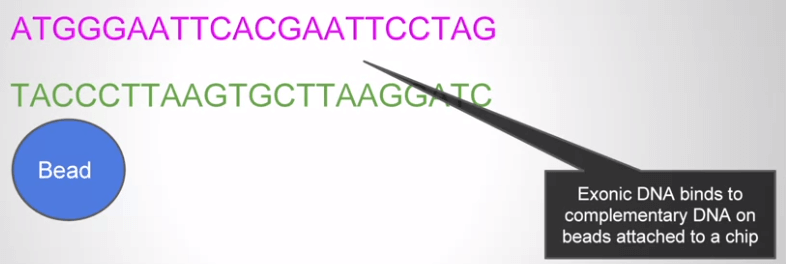
- 為了從一堆 DNA fragment 中取出 exons 的部分
- 有一個 magnetic bead 的工具
- Bead 上有 DNA 中的 exon 部分
- 我們將要測試的 DNA 加熱變成 single-strand
- Exons 會和 bead 上的對應 DNA 結合 (hybridize)
- 接著就可以把這些 exons 取出進行定序

這樣就可以只定序到 exome (約 50 - 60 million bases)
RNA-Seq (RNA sequencing)
為了找出哪些 DNA 真的產生蛋白質,可以從哪些 DNA 變成 RNA 開始找起
DNA 在 transcribe 成 RNA 會得到很長的 poly-A tail
所以我們用很長的 Ts 和 As 結合,然後用一些方法把 RNA 從 Ts 拿起來

要定序 RNA 要先轉回 DNA (需要一些病毒所擁有的 reverse transcriptase 幫助)
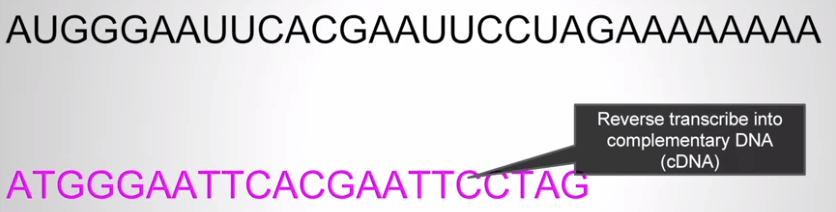
有了從 RNA 轉回的 DNA,就可以進行定序

再來就可以解決更難的問題,例如找出被該 RNA 啟動的功能
ChIP-Seq
ChIP-Seq 目標是找出 DNA 哪個位置會和蛋白質 (e.g. transcription factors) 結合 (影響 gene expression)
首先找出感興趣的細胞,利用 cross-link 將蛋白質結合 DNA
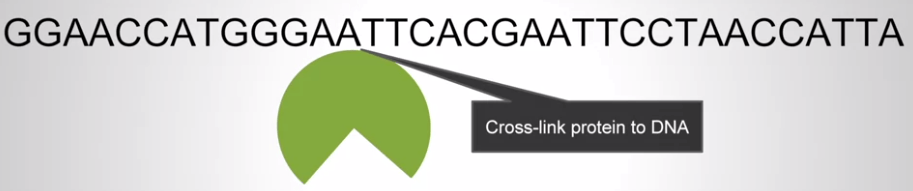
接著將 DNA 拆成一片一片,有的沒有蛋白質結合,有的有結合

然後將特製的 antibodies 放入這群 DNA 碎片中,他會將有蛋白質結合的 DNA 拉出來

然後就可以把蛋白質移除,對 DNA 定序 !
Bisulfate sequencing (methylseek)
目標是找出 genome 何處被 methylated (甲基化)
- Methylation 是很重要的 epigenetic modification
- 也影響了哪些蛋白質會被產生
- Methylation marks (methyl groups) 可因細胞分裂來傳遞
- Methyl groups 只會附在 Cytosine (C) 上面
首先將 DNA 分成兩個相等的樣本

對一邊進行 bisulfite conversion,會將沒有甲基化的 C 轉換成 U

然後對兩邊都進行定序,定序同時需要 aligner 幫助對齊比對 (將 U 和原本 C 的位置對齊)
